In large-scale data platforms, too many small files can become a production reliability issue, increasing metadata overhead, amplifying reads, driving higher tail latency, and causing job failures.
Small File Doctor is Binance’s in-house framework that turns small-file cleanup from scattered scripts into a governed system, reducing small files from about 59 million to 2.9 million and saving around $90,000 to $100,000 per year in compute and storage costs.
The core design goal is to make file optimization safe to run continuously in production while focusing effort only where it measurably improves latency, stability, and cost.
Modern platforms run on data pipelines. “Production” in this context means the always-on systems that ingest, transform, and serve data used by real products – monitoring, fraud detection, analytics, customer support, finance, and many other workflows that need to complete on schedule. When those pipelines slow down or fail, the impact shows up as delayed dashboards, missed service-level agreements, degraded user experience, or reduced ability to detect issues quickly.
One of the most common causes of hidden performance degradation in large data warehouses is small files. As data systems scale, frequent writes and partitioned storage can create tens of thousands of files per table or partition, each only a few KB to a few MB. The result is a system that spends more time opening files, reading metadata, and scheduling work than doing useful computation.
This post explains how Binance productized small-file optimization into a production framework, Small File Doctor, and why a “platform solution” is often the only reliable answer once the number of tables and partitions grows beyond what ad hoc scripts can handle.
Small files are not inherently bad. They become a problem when the count grows so large that the platform pays a fixed cost repeatedly: listing files, reading metadata, opening connections, and scheduling tasks. In distributed processing engines, those fixed costs compound, especially when downstream jobs scan many partitions at once.
That combination – lots of partitions and lots of small files inside each – increases read amplification and makes tail latency worse. Tail latency matters because a pipeline usually finishes only as fast as its slowest stage. Once the 99th-percentile time grows unstable, teams see missed service-level arrangements (SLAs), retries, out-of-memory errors, and intermittent failures that are difficult to reproduce.
The challenge is that small-file cleanup is easy to describe but hard to run safely at scale. Rewriting data in bulk touches storage, compute, and query engines. Without guardrails, a well-intended “merge files” job can become a new source of incidents.
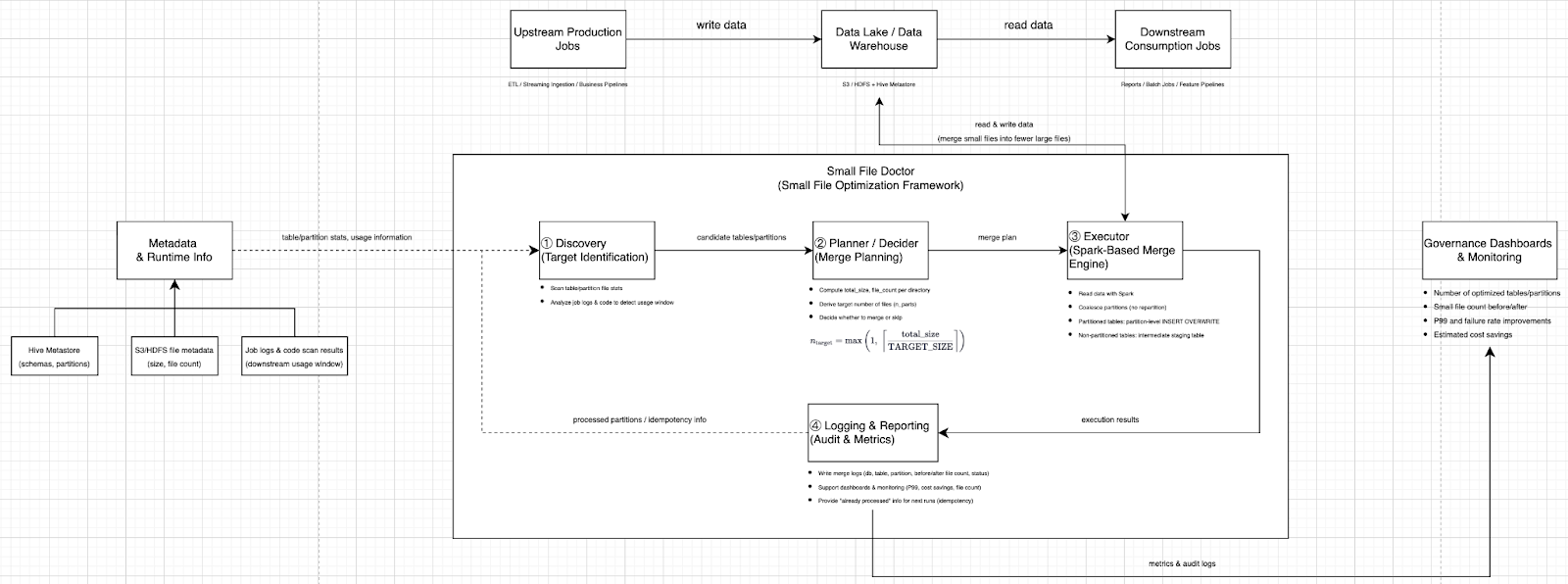
Small File Doctor is an internal framework that continuously identifies where small files actually matter, safely rewrites the underlying data into healthier file sizes, and logs every action so teams can measure impact.
There are three main goals:
Improve performance by converging file sizes toward a reasonable target – in our case, around 256 MB – which reduces metadata overhead and read amplification.
Reduce operational burden by automatically discovering hotspots and supporting different table layouts.
Provide governance: every rewrite is recorded so optimization can be tied to measurable outcomes like latency, stability, and cost.
In a large warehouse, the main risk is spending resources “cleaning” tables that do not affect production outcomes. Small File Doctor starts by identifying candidates using storage metadata and usage signals, then narrows the focus using how data is consumed in practice.
First, it inspects storage metadata from systems like S3 and HDFS to calculate file counts and size distributions across tables and partitions. This surfaces obvious hotspots, such as directories with very high file counts and a large share of tiny files.
Next, it prioritizes based on access patterns. The most damaging small-file cases usually happen when a job scans a wide window of partitions in one run, and each partition is filled with small files. That is what drives the worst metadata overhead and the biggest IO pressure. By contrast, a table where downstream jobs only ever read the latest partition rarely becomes a dominant tail-latency driver.
To estimate the real consumption window, the system analyzes Spark, Hive, and ETL code paths and job behavior to infer whether jobs scan one day, seven days, thirty days, or more in a single run. Tables that consistently behave like “T minus 1 only” are typically excluded. This is less about purity and more about ROI: optimize where it moves latency and stability rather than where it feels tidy.
Finally, selected tables and partition ranges are written into a configuration table that acts as an optimization backlog, with statuses that make it safe to process in controlled batches.
At a smaller scale, teams often rely on for-loop scripts, iterating through tables, rewriting files, and hoping nothing breaks. At Binance scale, this approach can become fragile. There is no clear record of what ran, whether it helped, which tables matter most, or how to keep the work from interfering with production workloads.
Small File Doctor replaces that with a continuously running workflow: take an explicit optimization backlog, compute directory-level stats, decide whether a merge is worth performing, execute safely, and log results for measurement and audit.
For each target directory – typically one partition for partitioned tables, or the full directory for non-partitioned tables – the framework estimates what a healthy file count would be under a target file size, then compares it to the actual file count and average file size.
It also includes basic safety rules to prevent wasted work, such as skipping directories that are too large for the configured time window, avoiding merges when there is only one file, and requiring that the average file size is materially below the target before triggering a rewrite. These controls are designed to prevent the system from repeatedly reprocessing the same directories with minimal benefit.
The execution principle is “merge without changing business logic, and never risk reading and overwriting the same data path at the same time.”
The framework reads data using Spark, coalesces it to reduce output files without forcing expensive global shuffles, and writes results back through SQL or Hive table semantics. That matters because the SQL layer can enforce safety constraints around overwrite behavior and reduces the chance of accidental read-write conflicts.
Partitioned tables are handled at the partition directory level. The system reads only the target partition, coalesces output, registers a temporary view, and overwrites that partition through SQL semantics so only the intended slice is touched.
Non-partitioned tables are trickier because there is a single directory. The framework avoids unsafe “read and overwrite same path” patterns by using a fixed staging table with the same schema. Data is written to staging first, then safely overwritten back into the original table from staging, keeping read and write paths separated.
Because this is bulk rewriting, production guardrails are essential. The framework limits concurrency to avoid overloading clusters, runs within defined off-peak windows, and avoids optimizing hot partitions that may still be actively written.
It also maintains a governance log that tracks before-and-after file counts, timestamps, and job status per table and partition. That enables idempotent behavior – a partition is optimized at most once – and supports resuming work after interruptions without duplicating effort.
Small File Doctor has already optimized 533 tables, reduced small files from about 59 million to 2.9 million, and eliminated read-stage failures linked to small files in the workloads tracked. Based on downstream cost models, the first layer of jobs alone is estimated to save around $90,000 to $100,000 annually, with additional upside as coverage expands.
Today, Small File Doctor runs asynchronously during off-peak windows, which keeps it decoupled from upstream production pipelines. The tradeoff is timing: downstream jobs on the same day may still run against unmerged partitions.
The next phase is deeper scheduler integration, where a partition is merged and validated immediately after it is produced, and only then marked ready for downstream consumption. This would turn file health into a built-in step of the production definition of “done,” bringing performance improvements closer to real-time.
At Binance’s scale, small files stop being housekeeping and become an infrastructure constraint: they increase tail latency, destabilize jobs, and waste compute overhead. Addressing that reliably requires a governed system that prioritizes the right data, rewrites safely, and ties work to measurable outcomes.
Small File Doctor reflects a broader pattern in production engineering: once a bottleneck becomes systemic, the solution needs to be systemic too. Building these kinds of internal frameworks is part of how Binance keeps critical pipelines reliable as products, users, and activity all scale at the same time.