

Acerca de ZKML: ZKML (Zero Knowledge Machine Learning) es una tecnología de aprendizaje automático que combina pruebas de conocimiento cero y algoritmos de aprendizaje automático para resolver problemas de protección de la privacidad en el aprendizaje automático.
Acerca de la potencia informática distribuida: la potencia informática distribuida se refiere a descomponer una tarea informática en varias tareas pequeñas y asignar estas pequeñas tareas a varias computadoras o procesadores para su procesamiento y lograr una informática eficiente.

La situación actual de la IA y la Web3: enjambre de abejas fuera de control y aumento de la entropía
En "Fuera de control: la nueva biología de las máquinas, la sociedad y la economía", Kevin Kelly propuso una vez un fenómeno: la colonia de abejas tomará decisiones electorales en un baile grupal de acuerdo con la gestión distribuida, y toda la colonia de abejas seguirá a este grupo. El enjambre más grande del mundo domina un evento. Esta es también la llamada "alma de la colonia de abejas" mencionada por Maurice Maeterlinck: cada abeja puede tomar su propia decisión y guiar a otras abejas para que la confirmen, y la decisión final es verdaderamente del grupo.

La ley del aumento de la entropía y del desorden en sí sigue la ley de la termodinámica. La realización teórica en física es colocar un cierto número de moléculas en una caja vacía y medir el perfil de distribución final. Específicamente para las personas, las multitudes generadas por algoritmos pueden mostrar reglas grupales a pesar de las diferencias individuales en el pensamiento. A menudo están restringidas en una caja vacía debido a factores como los tiempos, y eventualmente tomarán decisiones por consenso.
Por supuesto, las reglas del grupo pueden no ser correctas, pero los líderes de opinión que pueden representar el consenso y pueden construirlo por sí solos son absolutamente súper individuos. Pero en la mayoría de los casos, el consenso no persigue el consentimiento completo e incondicional de todos, sino que sólo requiere el reconocimiento general del grupo.
No estamos aquí para discutir si la IA desviará a los humanos. De hecho, ya hay muchas discusiones de este tipo, ya sea la gran cantidad de basura generada por las aplicaciones de inteligencia artificial que ha contaminado la autenticidad de los datos de la red o los errores en el grupo. toma de decisiones que conducirá a algunos El incidente tomó un giro más peligroso.
La situación actual de la IA tiene un monopolio natural. Por ejemplo, la formación y el despliegue de grandes modelos requieren una gran cantidad de recursos informáticos y datos, y sólo un pequeño número de empresas e instituciones cuentan con estas condiciones. Estos miles de millones de datos son considerados tesoros por todos los propietarios de monopolios. Sin mencionar el intercambio de código abierto, incluso el acceso mutuo es imposible.
Esto provoca un enorme desperdicio de datos. Cada proyecto de IA a gran escala requiere una recopilación repetida de datos de los usuarios. Al final, el ganador se lo queda todo, ya sean fusiones y adquisiciones, ventas, expansión de proyectos gigantes individuales o la Internet tradicional. La lógica de las carreras de rodeo.
Mucha gente dice que AI y Web3 son dos cosas diferentes y no tienen conexión alguna. La primera mitad de la oración es correcta. Son dos caminos diferentes, pero la segunda mitad de la oración es problemática. El monopolio de la inteligencia artificial terminará y utilizar la tecnología de inteligencia artificial para promover la formación de un mecanismo de consenso descentralizado es simplemente algo natural.
Deducción de nivel inferior: deje que la IA forme un mecanismo de consenso grupal verdaderamente distribuido
El núcleo de la inteligencia artificial todavía reside en las propias personas. Las máquinas y los modelos son sólo especulaciones e imitaciones del pensamiento humano. En realidad, es difícil abstraer al llamado grupo del grupo, porque lo que vemos todos los días son individuos reales. Pero el modelo utiliza enormes cantidades de datos para aprender y ajustarse, y finalmente simula la forma del grupo. No es necesario evaluar los resultados de este modelo, porque los incidentes de maldad grupal no ocurren una o dos veces. Pero el modelo sí representa el surgimiento de este mecanismo de consenso.
Por ejemplo, para un DAO específico, si la gobernanza se implementa como un mecanismo, inevitablemente tendrá un impacto en la eficiencia. La razón es que la formación de un consenso grupal es algo problemático, sin mencionar las votaciones, las estadísticas, etc. operaciones. Si la gobernanza de DAO se materializa en la forma de un modelo de IA, y toda la recopilación de datos proviene de los datos de voz de todos en la DAO, entonces las decisiones de salida estarán más cercanas al consenso del grupo.
El consenso grupal de un modelo único se puede utilizar para entrenar el modelo de acuerdo con el esquema anterior, pero para estos individuos, después de todo, todavía son islas aisladas. Si existe un sistema de inteligencia colectiva para formar una IA grupal, cada modelo de IA en este sistema trabajará en colaboración entre sí para resolver problemas complejos, lo que en realidad desempeñará un papel importante en el fortalecimiento del nivel de consenso.
Para colecciones pequeñas, puede construir un ecosistema de forma independiente o puede formar un conjunto cooperativo con otras colecciones para satisfacer potencias informáticas ultragrandes o transacciones de datos de manera más eficiente y a bajo costo. Pero el problema vuelve a surgir. La situación actual entre varios modelos de bases de datos es de total desconfianza y protección contra los demás. Este es el atributo natural de la cadena de bloques: a través de la desconfianza, se puede lograr una seguridad verdaderamente distribuida entre las máquinas de IA.
Un cerebro inteligente global puede hacer que modelos de algoritmos de IA que originalmente son independientes entre sí y tienen funciones únicas cooperen entre sí y ejecuten procesos de algoritmos inteligentes complejos internamente, para formar continuamente una red de consenso de grupo distribuido. Ésta es también la mayor importancia del empoderamiento de la Web3 por parte de la IA.
¿Privacidad y monopolio de datos? La combinación de ZK y aprendizaje automático
Los seres humanos deben tomar precauciones específicas contra las malas acciones de la IA o el miedo al monopolio de los datos debido a la protección de la privacidad. El problema central es que no sabemos cómo se llega a la conclusión. De manera similar, los operadores del modelo no tienen la intención de responder preguntas sobre este problema. Para la integración del cerebro inteligente global que mencionamos anteriormente, este problema debe resolverse aún más; de lo contrario, ninguna parte de los datos estará dispuesta a compartir su núcleo con otros.
ZKML (Zero Knowledge Machine Learning) es una tecnología que utiliza prueba de conocimiento cero para el aprendizaje automático. Las pruebas de conocimiento cero (ZKP) significan que el probador puede hacer que el verificador crea en la autenticidad de los datos sin revelar los datos específicos.
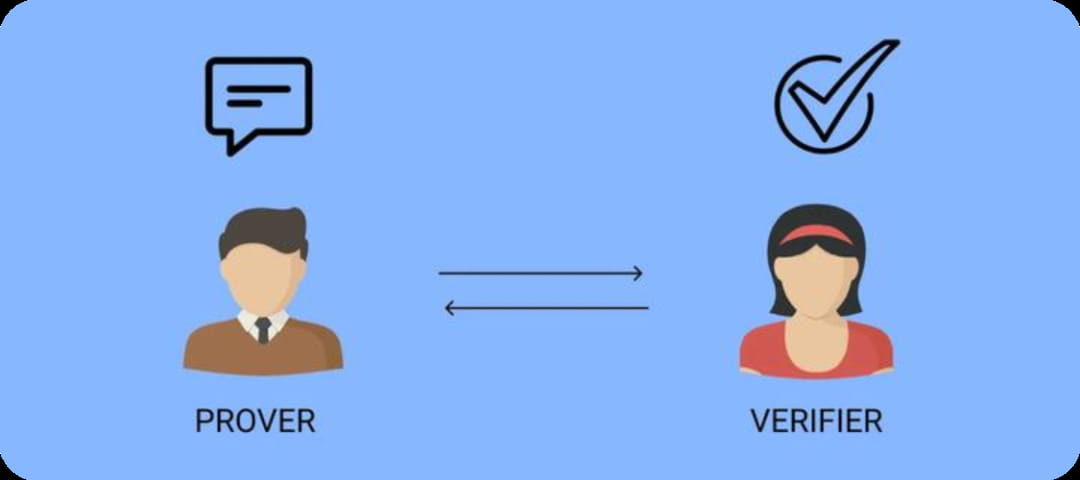
Tomar casos teóricos como guía. Hay un Sudoku estándar de 9 × 9. La condición para completarlo es completar las nueve cuadrículas con números del 1 al 9 para que cada número solo pueda aparecer una vez en cada fila, columna y cuadrícula. Entonces, ¿cómo demuestra la persona que creó este rompecabezas a los retadores que el sudoku tiene una solución sin revelar la respuesta?
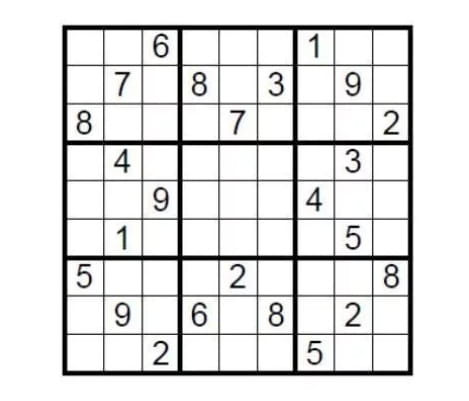
Simplemente cubra el relleno con la respuesta y luego deje que el retador seleccione al azar algunas filas o columnas, mezcle todos los números y verifique si todos son del uno al nueve. Esta es una implementación simple de la prueba de conocimiento cero.
La tecnología de prueba de conocimiento cero tiene tres características: integridad, corrección y conocimiento cero, lo que significa que prueba la conclusión sin revelar ningún detalle. Su fuente técnica puede reflejar simplicidad. En el contexto del cifrado homomórfico, la dificultad de verificación es mucho menor que la dificultad de generar pruebas.
Machine Learning utiliza algoritmos y modelos para permitir que los sistemas informáticos aprendan y mejoren a partir de los datos. Al aprender de la experiencia de forma automatizada, el sistema puede realizar automáticamente tareas como predicción, clasificación, agrupación y optimización basadas en datos y modelos.
En esencia, el aprendizaje automático radica en la construcción de modelos que aprenden de los datos y hacen predicciones y decisiones automáticamente. La construcción de estos modelos suele requerir tres elementos clave: conjuntos de datos, algoritmos y evaluación del modelo. Los conjuntos de datos son la base del aprendizaje automático y contienen muestras de datos que se utilizan para entrenar y probar modelos de aprendizaje automático. Los algoritmos son el núcleo de los modelos de aprendizaje automático y definen cómo el modelo aprende y predice a partir de los datos. La evaluación del modelo es una parte importante del aprendizaje automático, que se utiliza para evaluar el rendimiento y la precisión del modelo y decidir si es necesario optimizarlo y mejorarlo.

En el aprendizaje automático tradicional, los conjuntos de datos generalmente deben recopilarse en un lugar centralizado para la capacitación, lo que significa que el propietario de los datos debe compartirlos con un tercero, lo que puede generar el riesgo de fuga de datos o de privacidad. Con ZKML, los propietarios de datos pueden compartir conjuntos de datos con otros sin filtrarlos. Esto se logra mediante el uso de pruebas de conocimiento cero.
Cuando se utiliza la prueba de conocimiento cero para potenciar el aprendizaje automático, el efecto debería ser predecible. Esto resuelve el problema de larga data de la caja negra de la privacidad y el monopolio de los datos: si la parte del proyecto puede hacer esto sin revelar la entrada de datos del usuario o detalles específicos de la misma. modelo después de completar la prueba y verificación, ¿puede cada colección compartir sus propios datos o modelo para funcionar sin filtrar datos privados? Por supuesto, la tecnología actual aún es temprana y definitivamente habrá muchos problemas en la práctica. Esto no nos impide imaginar, y muchos equipos ya la están desarrollando.
¿Conducirá esta situación a la libre prostitución de pequeñas bases de datos frente a grandes bases de datos? Cuando piensas en cuestiones de gobernanza, vuelves a nuestro pensamiento Web3. La esencia de Crypto es la gobernanza. Ya sea mediante un uso extensivo o compartiendo, debería recibir los debidos incentivos. Ya sea a través de los mecanismos Pow originales, PoS o los últimos PoR (mecanismos de prueba de reputación), el efecto de incentivo está garantizado.
Potencia informática distribuida: una narrativa innovadora entrelazada con mentiras y realidad
Las redes de potencia informática descentralizadas siempre han sido un escenario popular en el círculo del cifrado. Después de todo, los grandes modelos de IA requieren una potencia informática asombrosa, y las redes de potencia informática centralizadas no solo causarán un desperdicio de recursos sino que también formarán un monopolio virtual, en comparación con In. Al final, lo único que importa es la cantidad de GPU, lo cual es demasiado aburrido.
La esencia de una red informática descentralizada es integrar recursos informáticos dispersos en diferentes ubicaciones y dispositivos. Las principales ventajas que todos mencionan a menudo son: proporcionar capacidades informáticas distribuidas, resolver problemas de privacidad, mejorar la credibilidad y confiabilidad de los modelos de inteligencia artificial, respaldar una implementación y operación rápidas en diversos escenarios de aplicaciones y proporcionar soluciones de administración y almacenamiento de datos. Así es, a través de la potencia informática descentralizada, cualquiera puede ejecutar modelos de IA y probarlos en conjuntos de datos reales en cadena de usuarios globales, para poder disfrutar de servicios informáticos más flexibles, eficientes y de bajo costo.
Al mismo tiempo, la potencia informática descentralizada puede resolver problemas de privacidad al crear un marco poderoso para proteger la seguridad y privacidad de los datos del usuario. También proporciona un proceso informático transparente y verificable, mejora la credibilidad y confiabilidad de los modelos de inteligencia artificial y proporciona recursos informáticos flexibles y escalables para una rápida implementación y operación en diversos escenarios de aplicaciones.
Consideramos el entrenamiento de modelos a partir de un conjunto completo de procesos informáticos centralizados. Los pasos generalmente se dividen en: preparación de datos, segmentación de datos, transmisión de datos entre dispositivos, entrenamiento en paralelo, agregación de gradientes, actualización de parámetros, sincronización y entrenamiento repetido. En este proceso, incluso si la sala de computadoras centralizada utiliza un grupo de equipos informáticos de alto rendimiento para compartir tareas informáticas a través de conexiones de red de alta velocidad, los altos costos de comunicación se han convertido en una de las mayores limitaciones de las redes informáticas descentralizadas.
Por lo tanto, aunque la red de potencia informática descentralizada tiene muchas ventajas y potencial, el camino de desarrollo sigue siendo tortuoso según los costos de comunicación actuales y las dificultades operativas reales. En la práctica, realizar una red informática descentralizada requiere superar muchos problemas técnicos prácticos, ya sea cómo garantizar la confiabilidad y seguridad de los nodos, cómo administrar y programar de manera efectiva los recursos informáticos distribuidos o cómo lograr una transmisión y comunicación de datos eficiente, etc. , son probablemente todos grandes problemas a los que nos enfrentamos en la práctica.
Cola: Expectativas dejadas para los idealistas
Volviendo a la realidad empresarial, la narrativa de la integración profunda de AI y Web3 parece muy buena, pero el capital y los usuarios nos dicen con acciones más prácticas que este está destinado a ser un viaje de innovación extremadamente difícil, a menos que el proyecto pueda ser como OpenAI. aunque seamos fuertes, debemos contar con un patrocinador fuerte; de lo contrario, los gastos ilimitados en I+D y el modelo de negocio poco claro nos aplastarán por completo.
Tanto la IA como la Web3 se encuentran ahora en una etapa extremadamente temprana de desarrollo, al igual que la burbuja de Internet de finales del siglo pasado. No fue hasta casi diez años después que marcó oficialmente el comienzo de la verdadera edad de oro. McCarthy alguna vez fantaseó con diseñar inteligencia artificial con inteligencia humana en unas vacaciones, pero no fue hasta casi setenta años después que realmente dimos un paso crítico hacia la inteligencia artificial.
Lo mismo ocurre con Web3 + AI. Hemos determinado la dirección correcta y el tiempo hará el resto.
Cuando la marea del tiempo retrocede gradualmente, aquellas personas y cosas que permanecen en pie son las piedras angulares de nuestro viaje de la ciencia ficción a la realidad.