

Despre ZKML: ZKML (Zero Knowledge Machine Learning) este o tehnologie de învățare automată care combină dovezi fără cunoștințe și algoritmi de învățare automată pentru a rezolva problemele de protecție a confidențialității în învățarea automată.
Despre puterea de calcul distribuită: puterea de calcul distribuită se referă la descompunerea unei sarcini de calcul în mai multe sarcini mici și atribuirea acestor sarcini mici mai multor computere sau procesoare pentru procesare pentru a obține o calcul eficientă.

Situația actuală a AI și Web3: Roiul de albine scăpat de sub control și creșterea entropiei
În „Out of Control: The New Biology of Machines, Society and the Economy”, Kevin Kelly a propus odată un fenomen: colonia de albine va lua decizii electorale într-un dans de grup conform managementului distribuit, iar întreaga colonie de albine va urma acest grup. dansul Cel mai mare roi din lume domină un eveniment. Acesta este și așa-numitul „suflet al coloniei de albine” menționat de Maurice Maeterlinck – fiecare albină poate lua propria decizie și poate ghida alte albine să o confirme, iar decizia finală este cu adevărat cea a grupului.

Legea creșterii entropiei și a dezordinei în sine urmează legea termodinamicii. Realizarea teoretică în fizică este de a pune un anumit număr de molecule într-o cutie goală și de a măsura profilul final de distribuție. Specific oamenilor, mulțimile generate de algoritmi pot arăta reguli de grup în ciuda diferențelor individuale de gândire. Acestea sunt adesea restricționate din cauza unor factori precum vremurile și vor lua în cele din urmă decizii de consens.
Desigur, regulile de grup pot să nu fie corecte, dar liderii de opinie care pot reprezenta consensul și pot construi singuri consensul sunt super indivizi absoluti. Dar în cele mai multe cazuri, consensul nu urmărește consimțământul complet și necondiționat al tuturor, ci necesită doar recunoașterea generală a grupului.
Nu discutăm aici dacă inteligența artificială va duce în rătăcire pe oameni. De fapt, există deja multe astfel de discuții, fie că este vorba de cantitatea mare de gunoi generată de aplicațiile de inteligență artificială care a poluat autenticitatea datelor din rețea sau de greșelile în decizia de grup. -a face asta va duce la unele Incidentul a luat o turnură mai periculoasă.
Situația actuală a inteligenței artificiale are un monopol natural De exemplu, pregătirea și implementarea modelelor mari necesită o cantitate mare de resurse de calcul și date, iar doar un număr mic de companii și instituții au aceste condiții. Aceste miliarde de date sunt considerate comori de către fiecare proprietar de monopol, ca să nu mai vorbim de partajarea open source, chiar și accesul reciproc este imposibil.
Acest lucru are ca rezultat o uriașă risipă de date. Fiecare proiect de IA la scară largă necesită colectarea repetată a datelor despre utilizatori. . Logica curselor de rodeo.
Mulți oameni spun că AI și Web3 sunt două lucruri diferite și nu au nicio legătură. Prima jumătate a propoziției sunt două piste diferite, dar a doua jumătate a propoziției este problematică de inteligență artificială se va termina Iar utilizarea tehnologiei inteligenței artificiale pentru a promova formarea unui mecanism de consens descentralizat este pur și simplu un lucru natural.
Deducere la nivel inferior: Lăsați AI să formeze un mecanism de consens de grup cu adevărat distribuit
Miezul inteligenței artificiale se află încă în oamenii înșiși. Mașinile și modelele sunt doar speculații și imitații ale gândirii umane. Așa-numitul grup este de fapt greu de făcut abstracție de la grup, pentru că ceea ce vedem în fiecare zi sunt indivizi reali. Dar modelul folosește cantități masive de date pentru a învăța și ajusta și, în cele din urmă, simulează forma grupului. Nu este necesar să se evalueze rezultatele acestui model, deoarece incidentele de rău de grup nu se întâmplă o dată sau de două ori. Dar modelul reprezintă apariția acestui mecanism de consens.
De exemplu, pentru un anumit DAO, dacă guvernarea este implementată ca mecanism, va avea inevitabil un impact asupra eficienței Motivul este că formarea consensului de grup este un lucru supărător, ca să nu mai vorbim de vot, statistici etc. operațiuni. Dacă guvernarea DAO este întruchipată sub forma unui model AI și toată colectarea de date provine din datele de vorbire ale tuturor din DAO, atunci deciziile de ieșire vor fi de fapt mai aproape de consensul de grup.
Consensul de grup al unui singur model poate fi folosit pentru a antrena modelul conform schemei de mai sus, dar pentru acești indivizi, ei sunt încă insule izolate până la urmă. Dacă există un sistem de inteligență colectivă pentru a forma un IA de grup, fiecare model AI din acest sistem va lucra în colaborare unul cu celălalt pentru a rezolva probleme complexe, care de fapt vor juca un rol important în împuternicirea nivelului de consens.
Pentru colecțiile mici, puteți construi un ecosistem în mod independent sau puteți forma un set de cooperare cu alte colecții pentru a îndeplini puterea de calcul foarte mare sau tranzacțiile de date mai eficient și la costuri reduse. Dar problema apare din nou. Situația actuală între diferite baze de date model este neîncrederea totală și protecția împotriva altora. Acesta este atributul natural al blockchain-ului: prin neîncredere, se poate obține o interacțiune cu adevărat distribuită între mașinile AI.
Un creier inteligent global poate face modele de algoritmi AI care sunt inițial independente unul de celălalt și au funcții unice să coopereze între ele și să execute procese complexe de algoritm inteligent în interior, astfel încât să formeze continuu o rețea de consens de grup distribuit. Aceasta este, de asemenea, cea mai mare semnificație a împuternicirii de către AI a Web3.
Confidențialitate și monopolul datelor? Combinația dintre ZK și machine learning
Ființele umane trebuie să ia măsuri de precauție specifice împotriva faptelor rele ale AI sau a fricii de monopolul datelor din cauza protecției confidențialității. Problema principală este că nu știm cum se ajunge la concluzie. În mod similar, operatorii modelului nu intenționează să răspundă la întrebări despre această problemă. Pentru integrarea creierului inteligent global pe care l-am menționat mai sus, această problemă trebuie rezolvată și mai mult, altfel nicio parte de date nu va fi dispusă să-și împărtășească nucleul cu alții.
ZKML (Zero Knowledge Machine Learning) este o tehnologie care folosește dovezi de zero cunoștințe pentru învățarea automată. Zero-Knowledge Proofs (ZKP) înseamnă că probatorul îl poate determina pe verificator să creadă în autenticitatea datelor fără a dezvălui datele specifice.
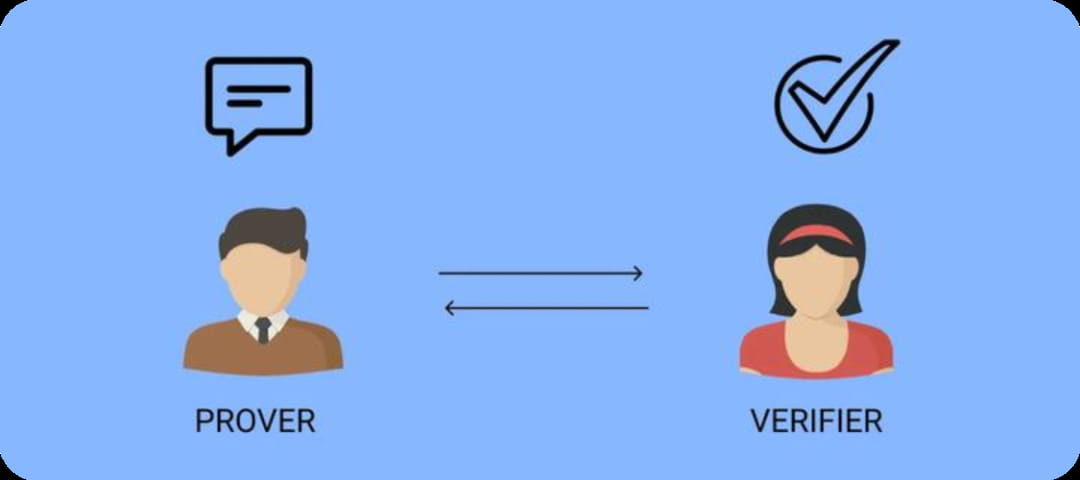
Luați cazuri teoretice drept ghid. Există un Sudoku standard 9×9 Condiția de finalizare este să completați cele nouă grile cu numere de la 1 la 9, astfel încât fiecare număr să poată apărea o singură dată în fiecare rând, coloană și grilă. Deci, cum le demonstrează persoana care a creat acest puzzle contestatorilor că sudoku-ul are o soluție fără a dezvălui răspunsul?
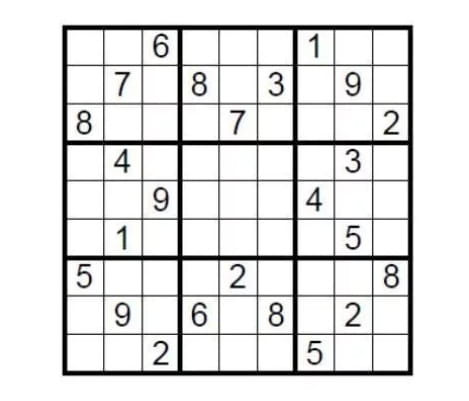
Doar acoperiți zona de umplere cu răspunsul, apoi cereți aleatoriu contestatorului să selecteze câteva rânduri sau coloane, amestecați toate numerele și verificați dacă toate sunt de la unu la nouă. Aceasta este o implementare simplă a dovezii zero-cunoștințe.
Tehnologia Zero-Kwledge proof are trei caracteristici: completitudine, corectitudine și zero-cunoaștere, ceea ce înseamnă că dovedește concluzia fără a dezvălui niciun detaliu. Sursa sa tehnică poate reflecta simplitatea În contextul criptării homomorfe, dificultatea verificării este mult mai mică decât dificultatea de a genera dovezi.
Machine Learning folosește algoritmi și modele pentru a permite sistemelor informatice să învețe și să se îmbunătățească din date. Învățând din experiență într-un mod automat, sistemul poate efectua automat sarcini precum predicția, clasificarea, gruparea și optimizarea bazate pe date și modele.
În esență, învățarea automată constă în construirea de modele care învață din date și iau automat predicții și decizii. Construirea acestor modele necesită de obicei trei elemente cheie: seturi de date, algoritmi și evaluarea modelului. Seturile de date sunt baza învățării automate și conțin eșantioane de date utilizate pentru antrenarea și testarea modelelor de învățare automată. Algoritmii sunt nucleul modelelor de învățare automată și definesc modul în care modelul învață și prezice din date. Evaluarea modelului este o parte importantă a învățării automate, utilizată pentru a evalua performanța și acuratețea modelului și pentru a decide dacă modelul trebuie optimizat și îmbunătățit.

În învățarea automată tradițională, seturile de date trebuie de obicei colectate într-un loc centralizat pentru instruire, ceea ce înseamnă că proprietarul datelor trebuie să partajeze datele cu o terță parte, ceea ce poate duce la riscul de scurgere de date sau de confidențialitate. Cu ZKML, proprietarii de date pot partaja seturi de date cu alții fără a scurge datele, ceea ce se realizează prin utilizarea dovezilor fără cunoștințe.
Atunci când dovada de cunoștințe zero este utilizată pentru a împuternici învățarea automată, efectul ar trebui să fie previzibil. Acest lucru rezolvă problemele de lungă durată ale cutiei negre de confidențialitate și monopolul datelor: dacă partea din proiect poate face acest lucru fără a scurge datele introduse de utilizator sau detaliile specifice ale acestuia. După finalizarea dovezilor și verificării, fiecare colecție poate să-și partajeze propriile date sau model pentru funcționare fără scurgeri de date private? Desigur, tehnologia actuală este încă devreme și cu siguranță vor fi multe probleme în practică. Acest lucru nu ne împiedică imaginația, iar multe echipe o dezvoltă deja.
Va duce această situație la prostituția liberă a bazelor de date mici împotriva bazelor de date mari? Când te gândești la problemele de guvernare, te întorci la gândirea noastră Web3. Esența Crypto este guvernarea. Fie că este vorba de utilizarea pe scară largă sau de partajare, ar trebui să primească stimulentele cuvenite. Fie prin mecanismele originale Pow, PoS sau prin cele mai recente mecanisme PoR (Proof of Reputation), efectul de stimulare este garantat.
Putere de calcul distribuită: o narațiune inovatoare împletită cu minciuni și realitate
Rețelele de putere de calcul descentralizate au fost întotdeauna un scenariu popular în cercul de criptare. La urma urmei, modelele mari de IA necesită o putere de calcul uimitoare, iar rețelele de putere de calcul centralizate nu numai că vor provoca o risipă de resurse, ci și vor forma un monopol virtual - în comparație cu In. la final, tot ce contează este numărul de GPU, ceea ce este prea plictisitor.
Esența unei rețele de calcul descentralizate este integrarea resurselor de calcul împrăștiate pe diferite locații și dispozitive. Principalele avantaje pe care toată lumea le menționează adesea sunt: furnizarea de capabilități de calcul distribuite, rezolvarea problemelor de confidențialitate, creșterea credibilității și fiabilității modelelor de inteligență artificială, susținerea implementării și operațiunilor rapide în diferite scenarii de aplicații și furnizarea de soluții de stocare și management descentralizate. Așa este, prin puterea de calcul descentralizată, oricine poate rula modele AI și le poate testa pe seturi de date reale în lanț de la utilizatori globali, astfel încât să se poată bucura de servicii de calcul mai flexibile, eficiente și cu costuri reduse.
În același timp, puterea de calcul descentralizată poate rezolva problemele de confidențialitate prin crearea unui cadru puternic pentru a proteja securitatea și confidențialitatea datelor utilizatorilor. De asemenea, oferă un proces de calcul transparent și verificabil, îmbunătățește credibilitatea și fiabilitatea modelelor de inteligență artificială și oferă resurse de calcul flexibile și scalabile pentru implementare și operare rapidă în diferite scenarii de aplicație.
Privim antrenarea modelului dintr-un set complet de procese de calcul centralizate. Pașii sunt de obicei împărțiți în: pregătirea datelor, segmentarea datelor, transmiterea datelor între dispozitive, antrenamentul în paralel, agregarea gradientului, actualizarea parametrilor, sincronizarea și antrenamentul repetat. În acest proces, chiar dacă sala de calculatoare centralizată folosește un cluster de echipamente de calcul de înaltă performanță pentru a partaja sarcini de calcul prin conexiuni de rețea de mare viteză, costurile mari de comunicare au devenit una dintre cele mai mari limitări ale rețelelor de calcul descentralizate.
Prin urmare, deși rețeaua de putere de calcul descentralizată are multe avantaje și potențial, calea de dezvoltare este încă sinuoasă pe baza costurilor actuale de comunicare și a dificultății reale de funcționare. În practică, realizarea unei rețele de calcul descentralizate necesită depășirea multor probleme tehnice practice, fie că este vorba despre cum să se asigure fiabilitatea și securitatea nodurilor, cum să se gestioneze și să programeze eficient resursele de calcul distribuite, fie cum să se realizeze o transmisie și o comunicare eficientă a datelor etc. , sunt probabil toate problemele mari cu care ne confruntăm în practică.
Coada: Au rămas așteptări pentru idealiști
Revenind la realitatea de afaceri, narațiunea integrării profunde a AI și Web3 arată atât de bine, dar capitalul și utilizatorii ne spun cu acțiuni mai practice că aceasta este destinată să fie o călătorie de inovare extrem de dificilă, cu excepția cazului în care proiectul poate fi ca OpenAI. în timp ce suntem puternici, ar trebui să îmbrățișăm un sponsor puternic, altfel cheltuielile fără fund de cercetare și dezvoltare și modelul de afaceri neclar ne vor zdrobi complet.
Atât AI, cât și Web3 se află acum într-un stadiu extrem de timpuriu de dezvoltare, la fel ca bula de internet de la sfârșitul secolului trecut. Abia după aproape zece ani a început oficial epoca de aur. McCarthy a visat cândva să proiecteze inteligența artificială cu inteligența umană într-o singură vacanță, dar abia după aproape șaptezeci de ani am făcut de fapt un pas critic către inteligența artificială.
Același lucru este valabil și pentru Web3+AI. Am stabilit corectitudinea direcției înainte, iar restul va fi lăsat la timp.
Când valul timpului se retrage treptat, acei oameni și lucruri care rămân în picioare sunt pietrele de temelie ale călătoriei noastre de la science fiction la realitate.