

Sobre ZKML: ZKML (Zero Knowledge Machine Learning) é uma tecnologia de aprendizado de máquina que combina provas de conhecimento zero e algoritmos de aprendizado de máquina para resolver problemas de proteção de privacidade no aprendizado de máquina.
Sobre o poder de computação distribuído: O poder de computação distribuído refere-se à decomposição de uma tarefa de computação em várias tarefas pequenas e à atribuição dessas pequenas tarefas a vários computadores ou processadores para processamento e obtenção de uma computação eficiente.

A situação atual da IA e da Web3: enxame de abelhas fora de controle e aumento da entropia
Em "Fora de Controle: A Nova Biologia das Máquinas, da Sociedade e da Economia", Kevin Kelly certa vez propôs um fenômeno: a colônia de abelhas tomará decisões eleitorais em uma dança de grupo de acordo com o gerenciamento distribuído, e toda a colônia de abelhas seguirá este grupo dança. O maior enxame do mundo domina um evento. Esta é também a chamada “alma da colônia de abelhas” mencionada por Maurice Maeterlinck – cada abelha pode tomar sua própria decisão e orientar outras abelhas para confirmá-la, e a decisão final cabe verdadeiramente ao grupo.

A própria lei do aumento e da desordem da entropia segue a lei da termodinâmica. A concretização teórica da física é colocar um certo número de moléculas em uma caixa vazia e medir o perfil de distribuição final. Específicas para as pessoas, as multidões geradas pelos algoritmos podem mostrar regras de grupo, apesar das diferenças individuais de pensamento. Muitas vezes, são limitadas a uma caixa vazia devido a fatores como o tempo e, eventualmente, tomarão decisões consensuais.
É claro que as regras do grupo podem não estar corretas, mas os líderes de opinião que podem representar o consenso e construir sozinhos o consenso são superindivíduos absolutos. Mas na maioria dos casos, o consenso não visa o consentimento completo e incondicional de todos, mas apenas requer o reconhecimento geral do grupo.
Não estamos discutindo aqui se a IA irá desviar os humanos. Na verdade, já existem muitas discussões desse tipo, seja a grande quantidade de lixo gerado por aplicativos de inteligência artificial que poluiu a autenticidade dos dados da rede, ou os erros na decisão do grupo. -fazer isso levará a alguns O incidente tomou um rumo mais perigoso.
A situação atual da IA tem um monopólio natural. Por exemplo, o treinamento e a implantação de grandes modelos exigem uma grande quantidade de recursos computacionais e dados, e apenas um pequeno número de empresas e instituições têm essas condições. Esses bilhões de dados são considerados tesouros por todos os proprietários de monopólios. Sem mencionar o compartilhamento de código aberto, mesmo o acesso mútuo é impossível.
Isto resulta num enorme desperdício de dados. Todo projeto de IA em grande escala exige a coleta repetida de dados do usuário. No final, o vencedor leva tudo – sejam fusões e aquisições, vendas, expansão de projetos gigantes individuais ou a Internet tradicional. . A lógica das corridas de rodeio.
Muitas pessoas dizem que IA e Web3 são duas coisas diferentes e não têm conexão. A primeira metade da frase está correta. São duas vias diferentes, mas a segunda metade da frase é problemática. da inteligência artificial acabará. E usar a tecnologia de inteligência artificial para promover a formação de um mecanismo de consenso descentralizado é simplesmente uma coisa natural.
Dedução de nível inferior: deixe a IA formar um mecanismo de consenso de grupo verdadeiramente distribuído
O núcleo da inteligência artificial ainda reside nas próprias pessoas. As máquinas e os modelos são apenas especulações e imitações do pensamento humano. O chamado grupo é realmente difícil de abstrair do grupo, porque o que vemos todos os dias são indivíduos reais. Mas o modelo usa grandes quantidades de dados para aprender e ajustar e, finalmente, simula a forma do grupo. Não é necessário avaliar os resultados deste modelo, porque os incidentes do mal de grupo não acontecem uma ou duas vezes. Mas o modelo representa a emergência deste mecanismo de consenso.
Por exemplo, para um DAO específico, se a governação for implementada como um mecanismo, terá inevitavelmente um impacto na eficiência. A razão é que a formação do consenso do grupo é uma coisa problemática, para não falar da votação, das estatísticas, etc. operações. Se a governança do DAO for incorporada na forma de um modelo de IA, e toda a coleta de dados vier dos dados de fala de todos no DAO, então as decisões de saída estarão realmente mais próximas do consenso do grupo.
O consenso do grupo de um único modelo pode ser usado para treinar o modelo de acordo com o esquema acima, mas para esses indivíduos, afinal, eles ainda são ilhas isoladas. Se houver um sistema de inteligência coletiva para formar uma IA de grupo, cada modelo de IA neste sistema trabalhará em colaboração entre si para resolver problemas complexos, o que na verdade desempenhará um grande papel no fortalecimento do nível de consenso.
Para coleções pequenas, você pode construir um ecossistema de forma independente ou formar um conjunto cooperativo com outras coleções para atender ao poder computacional ultragrande ou às transações de dados com mais eficiência e baixo custo. Mas o problema surge novamente. A situação atual entre vários bancos de dados modelo é de total desconfiança e proteção contra outros. Este é o atributo natural do blockchain: através da desconfiança, a segurança verdadeiramente distribuída entre as máquinas de IA pode ser alcançada.
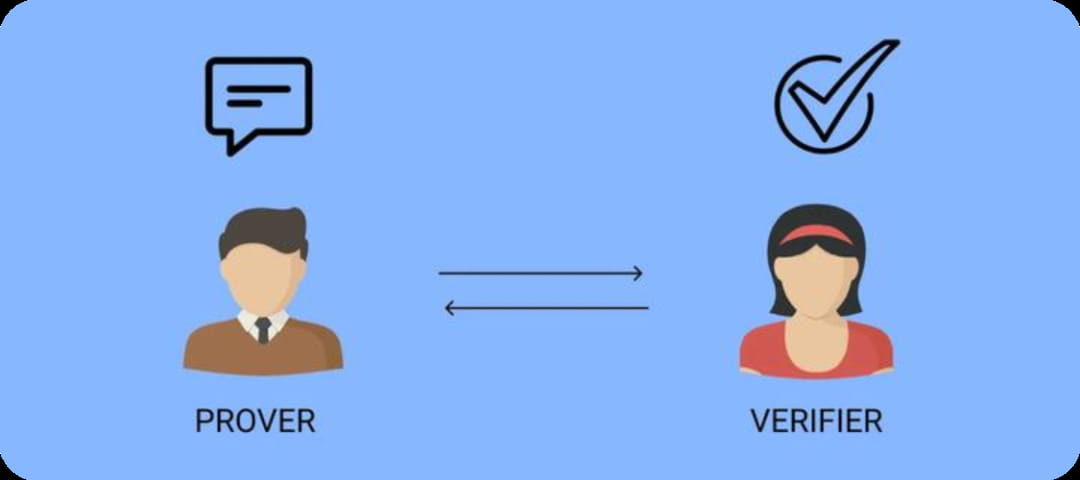
Um cérebro inteligente global pode fazer modelos de algoritmos de IA que são originalmente independentes uns dos outros e têm funções únicas, cooperando entre si e executando processos de algoritmos inteligentes complexos internamente, de modo a formar continuamente uma rede de consenso de grupo distribuída. Este é também o maior significado do fortalecimento da Web3 pela IA.
Privacidade e monopólio de dados? A combinação de ZK e aprendizado de máquina
Os seres humanos devem tomar precauções específicas contra as más ações da IA ou o medo do monopólio de dados devido à proteção da privacidade. O problema central é que não sabemos como se chega à conclusão. Da mesma forma, os operadores do modelo não pretendem responder a questões sobre este problema. Para a integração do cérebro inteligente global que mencionamos acima, este problema precisa ser ainda mais resolvido, caso contrário, nenhuma parte dos dados estará disposta a compartilhar seu núcleo com outras pessoas.
ZKML (Zero Knowledge Machine Learning) é uma tecnologia que usa prova de conhecimento zero para aprendizado de máquina. Provas de Conhecimento Zero (ZKP) significam que o provador pode fazer o verificador acreditar na autenticidade dos dados sem revelar os dados específicos.
Tome casos teóricos como guia. Existe um Sudoku padrão 9×9. A condição de conclusão é preencher as nove grades com números de 1 a 9 para que cada número possa aparecer apenas uma vez em cada linha, coluna e grade. Então, como é que a pessoa que criou este puzzle prova aos desafiantes que o sudoku tem uma solução sem revelar a resposta?
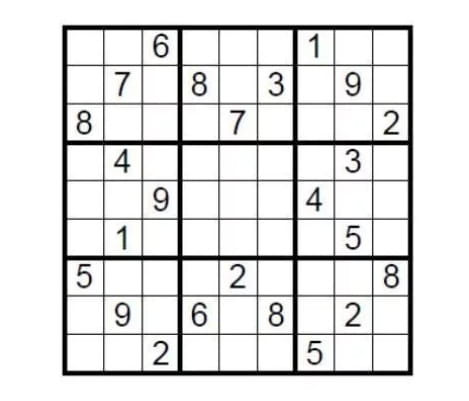
Basta cobrir a área de preenchimento com a resposta e, em seguida, pedir aleatoriamente ao desafiante para selecionar algumas linhas ou colunas, embaralhar todos os números e verificar se são todos de um a nove. Esta é uma implementação simples de prova de conhecimento zero.
A tecnologia de prova de conhecimento zero possui três características: completude, correção e conhecimento zero, o que significa que comprova a conclusão sem revelar quaisquer detalhes. Sua fonte técnica pode refletir simplicidade. No contexto da criptografia homomórfica, a dificuldade de verificação é muito menor do que a dificuldade de geração de provas.
O Machine Learning usa algoritmos e modelos para permitir que os sistemas de computador aprendam e melhorem a partir dos dados. Ao aprender com a experiência de forma automatizada, o sistema pode executar automaticamente tarefas como previsão, classificação, clustering e otimização com base em dados e modelos.
Basicamente, o aprendizado de máquina consiste na construção de modelos que aprendem com os dados e fazem previsões e decisões automaticamente. A construção destes modelos normalmente requer três elementos principais: conjuntos de dados, algoritmos e avaliação do modelo. Os conjuntos de dados são a base do aprendizado de máquina e contêm amostras de dados usadas para treinar e testar modelos de aprendizado de máquina. Os algoritmos são o núcleo dos modelos de aprendizado de máquina e definem como o modelo aprende e prevê a partir dos dados. A avaliação do modelo é uma parte importante do aprendizado de máquina, usada para avaliar o desempenho e a precisão do modelo e decidir se o modelo precisa ser otimizado e melhorado.

No aprendizado de máquina tradicional, os conjuntos de dados geralmente precisam ser coletados em um local centralizado para treinamento, o que significa que o proprietário dos dados deve compartilhar os dados com terceiros, o que pode levar ao risco de vazamento de dados ou de privacidade. Com o ZKML, os proprietários de dados podem compartilhar conjuntos de dados com outras pessoas sem vazar os dados. Isso é conseguido usando provas de conhecimento zero.
Quando a prova de conhecimento zero é usada para capacitar o aprendizado de máquina, o efeito deve ser previsível. Isso resolve os problemas de longa data da caixa preta de privacidade e do monopólio de dados: se a parte do projeto pode fazer isso sem vazar dados do usuário ou detalhes específicos do. modelo Depois de concluir a prova e verificação, cada coleção poderá compartilhar seus próprios dados ou modelo para funcionar sem vazar dados privados? É claro que a tecnologia atual ainda é inicial e com certeza haverá muitos problemas na prática. Isso não nos impede de imaginar, e muitas equipes já a estão desenvolvendo.
Esta situação levará à prostituição gratuita de pequenas bases de dados contra grandes bases de dados? Quando você pensa em questões de governança, você volta ao nosso pensamento Web3. A essência da criptografia é governança. Seja através do uso extensivo ou do compartilhamento, deve receber os devidos incentivos. Seja através dos mecanismos originais Pow, PoS ou dos mais recentes PoR (mecanismos de Prova de Reputação), o efeito de incentivo é garantido.
Poder de computação distribuído: uma narrativa inovadora entrelaçada com mentiras e realidade
Afinal, grandes modelos de IA exigem um poder de computação incrível, e redes de poder de computação centralizadas não apenas causarão um desperdício de recursos, mas também formarão um monopólio virtual - se comparadas a In. no final das contas, tudo o que importa é a quantidade de GPUs, o que é muito chato.
A essência de uma rede computacional descentralizada é integrar recursos computacionais espalhados em diferentes locais e dispositivos. As principais vantagens que todos mencionam frequentemente são: fornecer capacidades de computação distribuída, resolver problemas de privacidade, aumentar a credibilidade e fiabilidade dos modelos de inteligência artificial, apoiar a rápida implementação e operação em vários cenários de aplicações e fornecer soluções descentralizadas de armazenamento e gestão de dados. É isso mesmo, através do poder de computação descentralizado, qualquer pessoa pode executar modelos de IA e testá-los em conjuntos de dados reais em cadeia de utilizadores globais, para que possam desfrutar de serviços de computação mais flexíveis, eficientes e de baixo custo.
Ao mesmo tempo, o poder da computação descentralizada pode resolver problemas de privacidade, criando uma estrutura poderosa para proteger a segurança e a privacidade dos dados do usuário. Ele também fornece um processo de computação transparente e verificável, aumenta a credibilidade e a confiabilidade dos modelos de inteligência artificial e fornece recursos de computação flexíveis e escaláveis para rápida implantação e operação em vários cenários de aplicação.
Analisamos o treinamento do modelo a partir de um conjunto completo de processos de computação centralizados. As etapas geralmente são divididas em: preparação de dados, segmentação de dados, transmissão de dados entre dispositivos, treinamento paralelo, agregação de gradiente, atualização de parâmetros, sincronização e treinamento repetido. Neste processo, mesmo que a sala de informática centralizada utilize clusters de equipamentos de computação de alto desempenho e compartilhe tarefas de computação por meio de conexões de rede de alta velocidade, os altos custos de comunicação tornaram-se uma das maiores limitações das redes de computação descentralizadas.
Portanto, embora a rede descentralizada de poder computacional tenha muitas vantagens e potencial, o caminho de desenvolvimento ainda é tortuoso com base nos atuais custos de comunicação e na dificuldade real de operação. Na prática, a realização de uma rede informática descentralizada requer a superação de muitos problemas técnicos práticos, seja como garantir a fiabilidade e segurança dos nós, como gerir e programar eficazmente recursos computacionais distribuídos, ou como conseguir transmissão e comunicação de dados eficientes, etc. , são provavelmente todos grandes problemas que enfrentamos na prática.
Cauda: Expectativas deixadas para os idealistas
Voltando à realidade empresarial, a narrativa da integração profunda da IA e da Web3 parece tão boa, mas o capital e os utilizadores dizem-nos com ações mais práticas que esta está destinada a ser uma jornada de inovação extremamente difícil, a menos que o projeto possa ser como o OpenAI. embora sejamos fortes, devemos abraçar um patrocinador forte, caso contrário, as despesas ilimitadas de P&D e o modelo de negócios pouco claro nos esmagarão completamente.
Tanto a IA como a Web3 estão agora numa fase extremamente inicial de desenvolvimento, tal como a bolha da Internet no final do século passado. Só quase dez anos depois é que a verdadeira era de ouro começou oficialmente. McCarthy já sonhou em projetar inteligência artificial com inteligência humana em um feriado, mas foi só quase setenta anos depois que realmente demos um passo crítico em direção à inteligência artificial.
O mesmo se aplica ao Web3 + AI. Determinamos a correção da direção a seguir e o resto será deixado para o tempo.
Quando a maré do tempo recua gradualmente, as pessoas e coisas que permanecem de pé são os pilares da nossa jornada da ficção científica à realidade.