
Man mano che i sistemi di intelligenza artificiale diventano più autonomi, la questione della fiducia si sposta dai modelli ai dati. Non è più sufficiente sapere come è stato addestrato un modello. Devi sapere esattamente su quali dati è stato addestrato, se quei dati sono rimasti intatti e se qualcuno potrebbe averli modificati senza essere notato. Questo è il punto in cui la maggior parte delle pipeline di dati fallisce silenziosamente.
@Walrus 🦭/acc è costruito attorno a un'idea semplice ma potente: i dataset dovrebbero essere verificabili per impostazione predefinita, non fidati per assunzione.
Walrus non cerca di risolvere questo aggiungendo più monitoraggio o controllo degli accessi. Cambia il modo in cui i dati vengono impegnati, referenziati e riutilizzati tra i sistemi, in modo che la verifica diventi parte del flusso di lavoro stesso.
Perché i dataset tradizionali sono difficili da verificare
Nella maggior parte delle pipeline AI oggi, i dataset vivono in archiviazione centralizzata. I file vengono caricati, aggiornati, sovrascritti e versionati attraverso convenzioni piuttosto che garanzie. Anche quando i team tengono buoni registri, la verifica dipende comunque dalla fiducia.
Ti fidi che:
il dataset non è stato alterato dopo l'inizio dell'addestramento
l'etichetta della versione riflette effettivamente i dati sottostanti
il fornitore di archiviazione non ha sostituito o rimosso silenziosamente i record
Una volta che i modelli sono addestrati, dimostrare queste assunzioni diventa difficile. I log possono essere modificati. I file possono essere sostituiti. Le versioni precedenti possono non esistere più. Per i sistemi AI regolamentati o ad alto rischio, questa mancanza di verificabilità è una seria debolezza.
Walrus inizia assumendo che questo modello di fiducia sia insufficiente.
Impegnati prima, verifica per sempre
Al centro di Walrus c'è l'idea di impegni ai dati crittografici.
Quando un dataset viene aggiunto a Walrus, la rete concorda su una rappresentazione precisa di quei dati in quel momento. Questo impegno agisce come un'impronta digitale permanente. Se anche un singolo byte cambia in seguito, l'impegno non corrisponde più.
Per i flussi di lavoro dell'AI, questo significa che un lavoro di addestramento può fare riferimento a un impegno specifico del dataset invece di un percorso file mutevole. Chiunque esamini il modello in seguito può verificare in modo indipendente che i dati utilizzati per l'addestramento siano esattamente i dati che sono stati impegnati.
La verifica non dipende più da chi ha memorizzato i dati. Dipende dall'impegno stesso.
Disponibilità che non dipende da una singola parte
La verificabilità è priva di significato se i dati possono scomparire.
Walrus abbina impegni con disponibilità supportata dalla rete. I dati sono distribuiti e coordinati in modo che non possano essere trattenuti selettivamente o silenziosamente eliminati da un singolo attore. Se un partecipante va offline o si rifiuta di fornire dati, altri possono comunque fornirli.
Questo è importante per i dataset perché la disponibilità parziale può distorcere l'addestramento tanto quanto i dati errati. Un modello addestrato su un dataset incompleto può apparire corretto nei test ma comportarsi in modo imprevedibile in produzione.
Con Walrus, la disponibilità è una proprietà del sistema, non una promessa di un fornitore.
Versioning esplicito invece di sovrascritture silenziose
Uno dei modi più comuni in cui i dataset perdono integrità è attraverso la deriva della versione. Gli aggiornamenti sovrascrivono i file precedenti. Le etichette cambiano. Nel tempo, nessuno è sicuro di quale versione sia stata effettivamente utilizzata.
Walrus rende esplicito il versioning.
Ogni aggiornamento del dataset produce un nuovo impegno. Le versioni precedenti rimangono indirizzabili e verificabili. Niente viene sovrascritto. Questo crea una chiara genealogia dei cambiamenti dei dati nel tempo.
Per i team AI, questo significa:
puoi riprodurre l'addestramento esattamente
puoi controllare come i dataset si sono evoluti
puoi confrontare il comportamento del modello tra le versioni dei dati
È importante notare che questo non espone i dati pubblicamente. Espone l'esistenza e l'identità delle versioni, che è ciò che richiede la verificabilità.
Riferimenti verificabili attraverso il pipeline AI
Walrus tratta i riferimenti ai dati come oggetti di prima classe.
I lavori di addestramento, i modelli, gli agenti e i sistemi a valle possono tutti fare riferimento allo stesso impegno del dataset. Se un modello afferma di essere stato addestrato su un dataset specifico, tale affermazione può essere controllata in modo indipendente. Non c'è ambiguità su quali dati siano stati utilizzati.
Questo rimuove un'intera categoria di errori causati da file non corrispondenti, collegamenti interrotti o errori di coordinamento off-chain.
Per gli agenti autonomi, questo è particolarmente importante. Un agente che può verificare la propria fonte di dati è molto più affidabile di uno che si fida ciecamente dei sistemi a monte.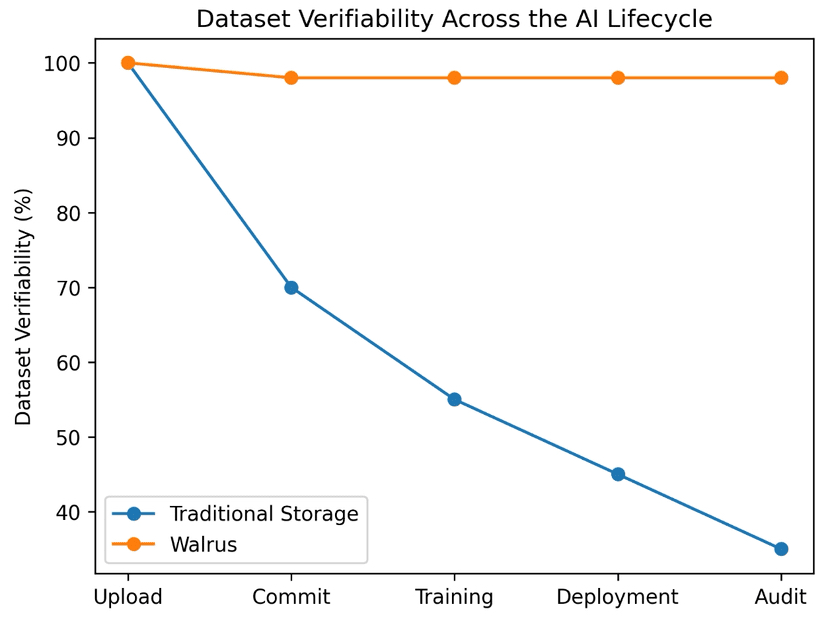
Perché questo è più importante man mano che l'AI diventa autonoma
Man mano che i sistemi AI passano da strumenti passivi a decisori attivi, il costo dell'incertezza dei dati aumenta bruscamente. Piccole incoerenze nei dati di addestramento possono tradursi in grandi differenze comportamentali. Quando il riaddestramento avviene automaticamente, la manipolazione diventa più facile e più difficile da rilevare.
Walrus abilita dataset che possono difendersi da soli.
Invece di chiedere “Ci fidiamo della fonte dei dati?”, i sistemi possono chiedere “Questi dati corrispondono al dataset impegnato?” Questo cambiamento trasforma la fiducia in verifica.
Dall'archiviazione alla credibilità dei dati
Walrus non si sta posizionando come un semplice strato di archiviazione. Si sta posizionando come infrastruttura di credibilità per i dati.
Combinando impegni immutabili, disponibilità garantita, versioning esplicito e riferimenti verificabili, Walrus rende i dataset qualcosa che può essere provato corretto molto tempo dopo la loro creazione.
Per l'addestramento, l'audit e il deployment dell'AI, questa è la differenza tra dati che speri siano corretti e dati su cui puoi effettivamente contare.
Il mio punto di vista
Le discussioni sulla sicurezza dell'AI si concentrano spesso su modelli, allineamento o limiti di calcolo. Ma i modelli sono a valle dei dati. Se i dati non possono essere verificati, nulla costruito su di essi è completamente affidabile.
Walrus affronta questo problema alla radice. Rendendo i dataset verificabili, persistenti e resistenti a cambiamenti silenziosi, fornisce ai sistemi AI qualcosa che finora è mancato: una base solida e provabile.
Man mano che i sistemi AI assumono più responsabilità, quella base sarà più importante di qualsiasi singolo aggiornamento del modello.