

À propos de ZKML : ZKML (Zero Knowledge Machine Learning) est une technologie d'apprentissage automatique qui combine des preuves sans connaissance et des algorithmes d'apprentissage automatique pour résoudre les problèmes de protection de la vie privée dans l'apprentissage automatique.
À propos de la puissance de calcul distribuée : la puissance de calcul distribuée fait référence à la décomposition d'une tâche informatique en plusieurs petites tâches et à l'attribution de ces petites tâches à plusieurs ordinateurs ou processeurs pour un traitement permettant d'obtenir un calcul efficace.

La situation actuelle de l’IA et du Web3 : essaim d’abeilles incontrôlable et augmentation de l’entropie
Dans « Hors de contrôle : la nouvelle biologie des machines, de la société et de l'économie », Kevin Kelly a un jour proposé un phénomène : la colonie d'abeilles prendra des décisions électorales dans une danse de groupe selon une gestion distribuée, et toute la colonie d'abeilles suivra ce groupe. danse. Le plus grand essaim du monde domine un événement. C'est aussi ce que l'on appelle « l'âme de la colonie d'abeilles » évoquée par Maurice Maeterlinck : chaque abeille peut prendre sa propre décision et guider d'autres abeilles pour la confirmer, et la décision finale appartient véritablement au groupe.

La loi de l'entropie croissante et du désordre elle-même suit les lois de la thermodynamique. Cette théorie, telle qu'elle est incarnée en physique, s'exprime en plaçant un certain nombre de molécules dans une boîte vide et en mesurant la distribution résultante. Plus précisément, des foules générées par algorithme, malgré des différences de pensée individuelles, peuvent également présenter des schémas de groupe. Souvent, en raison de facteurs tels que le temps, elles sont confinées dans une boîte vide et finissent par parvenir à des décisions consensuelles.
Bien sûr, les règles du groupe ne sont pas forcément exactes, mais elles peuvent représenter un consensus. Les leaders d'opinion capables de construire à eux seuls un consensus sont des individus véritablement exceptionnels. Cependant, dans la plupart des cas, le consensus ne requiert pas l'accord inconditionnel de tous ; il requiert simplement une reconnaissance universelle au sein du groupe.
Il ne s'agit pas ici de savoir si l'IA va égarer les humains. En réalité, de nombreux débats sur ce sujet existent déjà, qu'il s'agisse de la grande quantité de données inutiles générées par les applications d'intelligence artificielle, qui altèrent l'authenticité des données réseau, ou des erreurs de prise de décision collective susceptibles de conduire à des situations plus dangereuses.
L'IA actuelle est intrinsèquement monopolistique. Par exemple, l'entraînement et le déploiement de modèles de grande envergure nécessitent d'énormes quantités de ressources informatiques et de données, dont seul un petit nombre d'entreprises et d'institutions disposent. Ces milliards de données sont précieusement conservées par chaque détenteur de monopole, rendant impossible le partage open source, voire l'accès croisé.
Il en résulte un énorme gaspillage de données. Tout projet d'IA à grande échelle doit collecter à plusieurs reprises des données utilisateurs, et au final, le gagnant rafle la mise – qu'il s'agisse d'une fusion ou d'une acquisition, d'une vente, de l'expansion de projets géants individuels ou de la logique traditionnelle d'Internet, basée sur l'accaparement des terres et les courses de chevaux.
Beaucoup affirment que l'IA et le Web 3 sont deux choses différentes et n'ont aucun lien. La première partie de la phrase est correcte, car il s'agit de deux pistes distinctes, mais la seconde est problématique. Utiliser la technologie distribuée pour limiter le monopole de l'intelligence artificielle et utiliser la technologie de l'intelligence artificielle pour favoriser la formation d'un mécanisme de consensus décentralisé sont tout simplement naturels.
Déduction de bas niveau : laissez l’IA former un mécanisme de consensus de groupe véritablement distribué
Le cœur de l'intelligence artificielle réside dans l'humain ; les machines et les modèles ne font que spéculer et imiter la pensée humaine. S'il est difficile d'abstraire le concept de groupe, comme nous le voyons au quotidien, les modèles exploitent de vastes quantités de données pour apprendre et s'adapter, simulant ainsi la dynamique de groupe. S'il n'est pas certain que de tels modèles produisent des résultats néfastes, les incidents de mauvaise conduite collective n'étant pas rares, ils témoignent néanmoins de l'émergence d'un mécanisme de consensus.
Par exemple, si la gouvernance d'une DAO spécifique est mise en œuvre sous forme de mécanisme, l'efficacité en sera inévitablement affectée. En effet, parvenir à un consensus collectif est intrinsèquement complexe, sans parler de la série d'opérations requises, telles que le vote et les statistiques. Si la gouvernance de la DAO est implémentée sous forme de modèle d'IA, toutes les données collectées proviennent des avis de tous les membres de la DAO, et les décisions prises sont en réalité plus proches du consensus collectif.
Bien que des modèles individuels puissent être entraînés selon la même approche que celle décrite ci-dessus, ces individus restent isolés. Cependant, si les systèmes d'intelligence collective formaient une IA en essaim, où des modèles individuels collaboreraient pour résoudre des problèmes complexes, cela renforcerait considérablement le consensus.
Les petites collections peuvent soit construire des écosystèmes de manière indépendante, soit collaborer avec d'autres collections pour répondre plus efficacement et à moindre coût aux besoins de puissance de calcul ou de transactions de données à grande échelle. Cependant, le problème se pose à nouveau : l'état actuel des bases de données modèles est marqué par une méfiance et une méfiance totales les unes envers les autres. C'est précisément la caractéristique intrinsèque de la blockchain : grâce à la décentralisation, elle permet une interaction véritablement distribuée, sécurisée et efficace entre les machines d'IA.
Un cerveau intelligent mondial peut permettre à des modèles d'algorithmes d'IA jusqu'alors indépendants et monofonctionnels de collaborer, exécutant en interne des processus algorithmiques intelligents complexes, formant ainsi un réseau de consensus de groupe distribué en constante croissance. C'est également là l'importance majeure de l'autonomisation du Web3 par l'IA.
Confidentialité et monopole des données ? Combiner ZK et apprentissage automatique
Que ce soit par crainte du potentiel nocif de l'IA, de la confidentialité ou du monopole des données, l'humanité doit prendre des précautions ciblées. Le problème fondamental est que nous ignorons comment les conclusions sont tirées, et les opérateurs de modèles eux-mêmes sont réticents à aborder cette question. Cet enjeu est particulièrement urgent pour l'intégration du cerveau intelligent mondial mentionné précédemment, car sinon, aucun fournisseur de données ne serait disposé à partager ses données essentielles.
ZKML (Zero Knowledge Machine Learning) est une technologie qui applique des preuves à connaissance nulle à l'apprentissage automatique. Les preuves à connaissance nulle (ZKP) permettent à un prouveur de convaincre un vérificateur de l'authenticité des données sans les révéler.
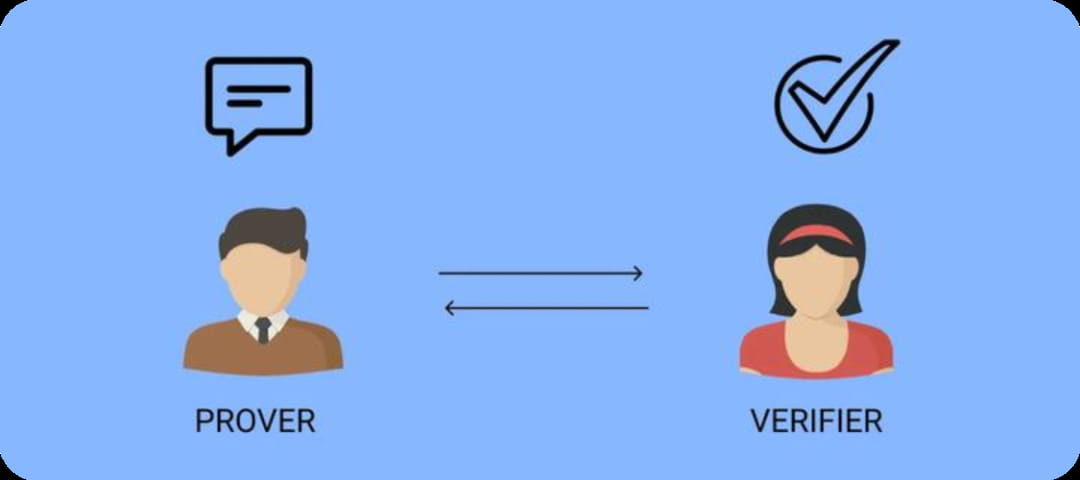
Prenons un exemple théorique. Prenons un Sudoku standard 9x9. Pour le résoudre, il faut remplir neuf cases avec des nombres de 1 à 9, en veillant à ce que chaque chiffre n'apparaisse qu'une seule fois par ligne, colonne et case. Alors, comment le joueur peut-il prouver à son adversaire que le puzzle a une solution sans révéler la réponse ?
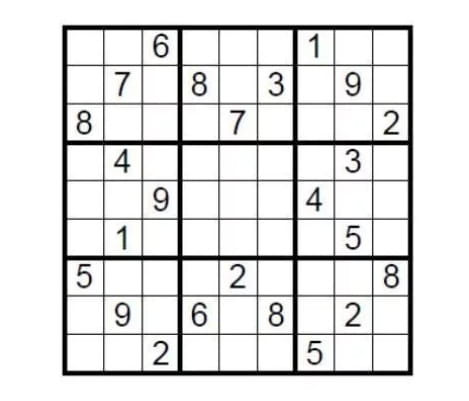
Il vous suffit de couvrir la zone de remplissage avec la réponse, puis de demander au challenger de choisir au hasard quelques lignes ou colonnes, de mélanger tous les nombres, puis de vérifier s'ils sont tous compris entre 1 et 9. Il s'agit d'une simple preuve à connaissance nulle.
La technologie de preuve à connaissance nulle se distingue par son exhaustivité, son exactitude et sa connaissance nulle, prouvant une conclusion sans révéler aucun détail. Ses racines technologiques sont particulièrement simples et, dans le contexte du chiffrement homomorphe, la vérification est bien plus simple que la génération de preuves.
L'apprentissage automatique utilise des algorithmes et des modèles pour permettre aux systèmes informatiques d'apprendre et de s'améliorer à partir des données. En automatisant l'apprentissage par l'expérience, les systèmes peuvent exécuter automatiquement des tâches telles que la prédiction, la classification, le clustering et l'optimisation en fonction des données et des modèles.
Le cœur de l'apprentissage automatique réside dans la construction de modèles capables d'apprendre à partir des données et de réaliser automatiquement des prédictions et des décisions. La construction de ces modèles nécessite généralement trois éléments clés : des ensembles de données, des algorithmes et une évaluation des modèles. Les ensembles de données constituent le fondement de l'apprentissage automatique, contenant les échantillons de données utilisés pour entraîner et tester les modèles. Les algorithmes sont au cœur des modèles d'apprentissage automatique, définissant la manière dont les modèles apprennent à partir des données et réalisent des prédictions. L'évaluation des modèles est une étape cruciale de l'apprentissage automatique, utilisée pour évaluer les performances et la précision des modèles et déterminer si des optimisations et des améliorations sont nécessaires.

Dans l'apprentissage automatique traditionnel, les ensembles de données doivent généralement être collectés dans un emplacement centralisé pour l'entraînement, ce qui implique que le propriétaire des données doit les partager avec un tiers, ce qui peut entraîner un risque de fuite de données ou de confidentialité. Avec ZKML, les propriétaires de données peuvent partager leurs ensembles de données avec d'autres sans les divulguer. Ceci est rendu possible grâce à la preuve à divulgation nulle de connaissance.
L'application de preuves à divulgation nulle de connaissance pour renforcer l'apprentissage automatique devrait avoir des effets prévisibles. Cela résout les problèmes persistants des boîtes noires de confidentialité et des monopoles de données : les projets peuvent-ils effectuer des preuves et des vérifications sans révéler les données saisies par les utilisateurs ni les détails spécifiques des modèles ? Chaque collection peut-elle partager ses propres données ou modèles sans divulguer de données privées ? Bien sûr, la technologie n'en est qu'à ses débuts et la pratique posera sans aucun doute de nombreux problèmes. Cependant, cela ne nous empêche pas de l'imaginer, et de nombreuses équipes la développent déjà.
Cette situation conduira-t-elle les petites bases de données à exploiter les grandes ? En matière de gouvernance, nous revenons à notre approche Web3. L'essence même de la cryptographie réside dans la gouvernance. Que ce soit par une utilisation généralisée ou par le partage, des incitations appropriées doivent être obtenues. Qu'il s'agisse des mécanismes existants de preuve de travail (PoW) et de preuve d'objet (PoS) ou des mécanismes plus récents de preuve de réputation (PoR), tous visent à garantir des incitations efficaces.
Puissance de calcul distribuée : un récit innovant mêlant mensonges et réalité
Les réseaux de puissance de calcul décentralisés ont toujours été un scénario populaire dans le monde de la cryptographie. Après tout, les grands modèles d'IA nécessitent une puissance de calcul impressionnante, et les réseaux de puissance de calcul centralisés non seulement gaspillent des ressources, mais forment également un monopole de fait. Si la compétition finale se limite au nombre de GPU, ce serait trop ennuyeux.
Un réseau informatique décentralisé intègre des ressources informatiques dispersées sur différents sites et appareils. Parmi les principaux avantages souvent cités figurent la puissance de calcul distribuée, la prise en compte des préoccupations en matière de confidentialité, l'amélioration de la crédibilité et de la fiabilité des modèles d'IA, la prise en charge d'un déploiement et d'une exploitation rapides dans divers scénarios d'application, et la fourniture de solutions décentralisées de stockage et de gestion des données. En effet, la puissance de calcul décentralisée permet à chacun d'exécuter des modèles d'IA et de les tester sur des ensembles de données réels, on-chain, provenant d'utilisateurs du monde entier, ce qui se traduit par des services informatiques plus flexibles, plus efficaces et plus rentables.
Parallèlement, la puissance de calcul décentralisée peut répondre aux enjeux de confidentialité en créant un cadre performant pour protéger la sécurité et la confidentialité des données des utilisateurs. Elle offre également un processus de calcul transparent et vérifiable, renforce la crédibilité et la fiabilité des modèles d'intelligence artificielle et fournit des ressources informatiques flexibles et évolutives pour un déploiement et une exploitation rapides dans divers scénarios d'application.
Si l'on considère l'apprentissage des modèles dans le cadre d'un processus informatique centralisé complet, les étapes sont généralement divisées comme suit : préparation des données, segmentation des données, transfert de données entre appareils, apprentissage parallèle, agrégation de gradients, mise à jour des paramètres, synchronisation et apprentissage répété. Au cours de ce processus, même si un centre de données centralisé utilise un cluster d'appareils de calcul haute performance et partage les tâches de calcul via une connexion réseau haut débit, les coûts de communication élevés restent une limitation majeure des réseaux informatiques décentralisés.
Par conséquent, malgré les nombreux avantages et le potentiel des réseaux informatiques décentralisés, leur développement reste tortueux compte tenu des coûts de communication actuels et des difficultés opérationnelles. Concrètement, la mise en place d'un réseau informatique décentralisé nécessite de surmonter de nombreux défis techniques, notamment la fiabilité et la sécurité des nœuds, la gestion et la planification efficaces des ressources informatiques distribuées, ainsi que l'efficacité de la transmission et de la communication des données. Ces défis sont tous considérables.
Fin : Attentes envers les idéalistes
Pour revenir à la réalité économique actuelle, le récit de l'intégration profonde de l'IA et du Web 3 paraît si beau, mais les capitaux et les utilisateurs nous ont montré, par des actions concrètes, que ce parcours d'innovation s'annonce extrêmement difficile. À moins que le projet ne soit comparable à OpenAI, fort de sa propre force et bénéficiant d'un soutien financier puissant, les coûts exorbitants de R&D et le manque de clarté du modèle économique nous anéantiront complètement.
L'IA et le Web3 en sont actuellement à leurs balbutiements, à l'image de la bulle Internet de la fin du siècle dernier, qui n'a véritablement atteint son âge d'or que près d'une décennie plus tard. McCarthy rêvait autrefois de concevoir une IA dotée d'une intelligence comparable à celle des humains en un seul voyage, mais il a fallu près de soixante-dix ans pour que nous fassions véritablement le premier pas vers l'IA.
Il en va de même pour Web3+IA. Nous avons déjà déterminé la bonne direction à prendre, et le reste dépendra du temps.
À mesure que le temps s’éloigne, les personnes et les choses qui restent debout deviendront les pierres angulaires de notre voyage de la science-fiction à la réalité.