Analyse de recherche originale de Web3.com Ventures
0xPoissonlosophe
Introduction
« zk-Rollups » a probablement été le mot à la mode du Web 3 de l'année. Avec le lancement du réseau principal v2.0 « baby alpha » de zk-Sync ces derniers jours, cet enthousiasme a atteint son apogée [1]. Mais derrière tous ces mots à la mode, à quoi font réellement référence les « zk-Rollups » ? Et où zk-Sync entre-t-il en jeu ? Dans cet article, je m'efforcerai d'approfondir les principes et la pratique de zk-Rollups, d'expliquer les principales caractéristiques techniques de zk-Sync v2.0 en tant que projet et d'explorer les implications futures potentielles de cette technologie tant attendue.
Principes des zk-Rollups
Pourquoi avons-nous besoin de zk-Rollups en premier lieu ? Bien sûr, Ethereum est génial. Mais dans son état actuel, le réseau constitue fondamentalement une déséconomie d’échelle. À mesure que l’activité du réseau augmente, les prix du gaz deviennent prohibitifs, en particulier si l’activité du réseau augmente d’un seul coup. Alors qu’Ethereum gagne en popularité et en popularité au cours des dernières années, son évolutivité limitée actuelle est devenue le talon d’Achille du réseau.
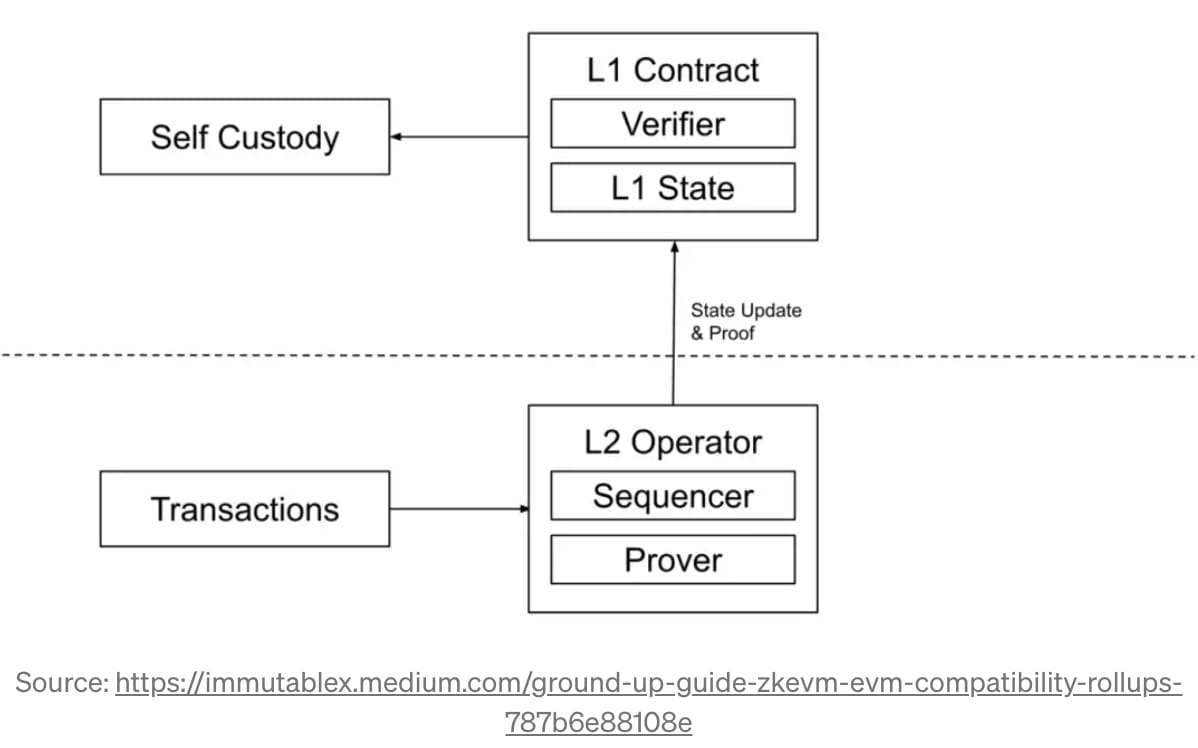
C’est là qu’interviennent les « rollups » – les rollups Ethereum sont essentiellement un « plugin » qui fournit à Ethereum des ampleurs supplémentaires d’évolutivité et corrige ainsi sa déséconomie d’échelle inhérente. L’intuition derrière l’idée est simple. Imaginez que vous ayez 5 objets que vous devez transporter d'un point A à un point B. La manière « normale » de le faire serait de transporter l'article 1, de transporter l'article 2, etc., l'un après l'autre. Mais cela est évidemment lent et fastidieux. Un « rollup » consiste essentiellement à « rouler » les 5 articles dans un seul sac, vous permettant ainsi de faire un seul voyage au lieu de 5.
Mais il y a deux mises en garde :
Comment pouvons-nous nous assurer que le rollup peut « s’adapter » à tout ?
Comment pouvons-nous nous assurer que le rollup n’est pas usurpé ?
Les zk-Rollups sont l'un des principaux types de technologies de cumul (l'autre étant les cumuls optimistes) tirant parti des « preuves de connaissance nulle » pour résoudre ces deux problèmes. Pour résoudre ces problèmes, un zk-Rollup regroupera un certain nombre de transactions, effectuera le calcul sur le L2 et soumettra à la fois les changements d'état et une « preuve de validité » à un vérificateur sur le L1 montrant que les calculs ont été effectués avec intégrité. . Cette « preuve de validité » prend la forme d’une « preuve de connaissance zéro », une manière mathématique de dire à quelqu’un que vous savez quelque chose sans lui dire ce que vous savez.
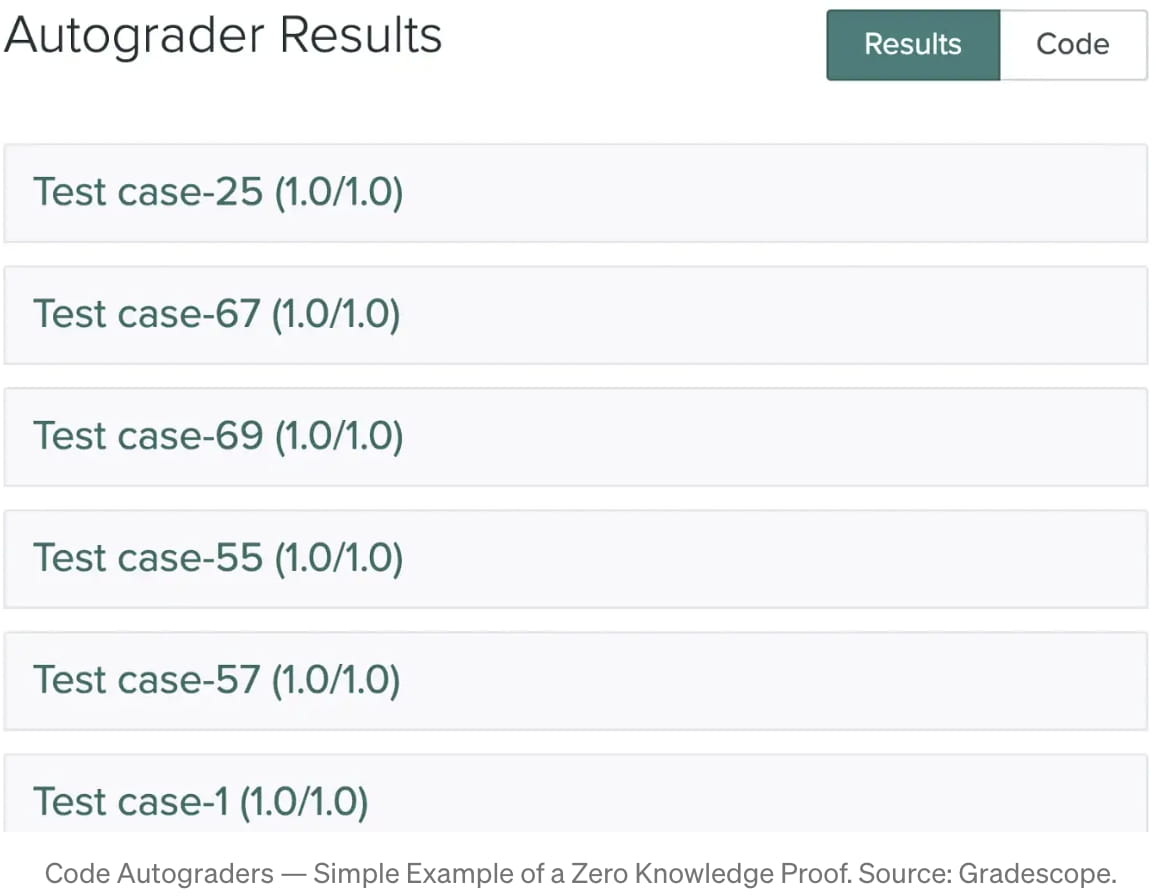
Un exemple simple de preuve de zéro connaissance est un niveleur automatique de code (pour les devoirs CS). L'autograder est un « vérificateur » qui vous donne un ensemble de cas de test générés aléatoirement, et vous êtes un « prouveur » qui doit être capable de réussir tous les cas de test pour prouver que vous avez le bon code. Pendant ce temps, vous ne partagez pas votre code directement avec l’autoniveleur. Et voilà, vous venez de réaliser une « Zero-Knowledge Proof », prouvant que vous savez quelque chose sans dire ce que vous savez. [2]
L'autoniveleur de code ci-dessus utilise un « Zero-Knowledge-Proof » interactif, dans lequel l'autoniveleur et le fournisseur de code « interagissent » directement les uns avec les autres. En revanche, la plupart des zk-Rollups utilisent une preuve non interactive plus compliquée mathématiquement (telle qu'un zk-SNARK, ou Zero Knowledge Succinct Noninteractive ARgument of Knowledge), qui permet d'économiser du temps et de l'espace par rapport à une preuve interactive. Bien que les détails techniques des zk-SNARK dépassent le cadre de cet article, le principe sous-jacent de la réussite des cas de test est le même.
Le Saint Graal de zk-Rollups est une machine virtuelle Ethereum à connaissance nulle (zk-EVM) qui permet aux développeurs de porter n'importe quel contrat intelligent Ethereum sans modification sur une chaîne zk-Rollup. Mais c'est difficile. Parce que chaque « problème » nécessite différents ensembles de « cas de test », le développement d'un « algorithme de preuve » capable de résoudre tous les cas de test imaginables est un goulot d'étranglement technique des preuves à connaissance nulle et des zk-Rollups.
Comme le dit Vitalik Buterin lui-même :
En général, mon propre point de vue est qu'à court terme, les cumuls optimistes sont susceptibles de l'emporter pour le calcul EVM à usage général et les cumuls ZK sont susceptibles de l'emporter pour les paiements simples, les échanges et d'autres cas d'utilisation spécifiques à l'application, mais dans le Les cumuls ZK à moyen et long terme l'emporteront dans tous les cas d'utilisation à mesure que la technologie ZK-SNARK s'améliore. [3]
Ainsi, historiquement, les zk-Rollups n'ont été que des technologies établies pour des cas d'utilisation spécifiques à des applications, où les « cas de test » sont bien définis et de portée limitée. Cependant, plusieurs projets avancent rapidement vers le « château sur la colline » – un algorithme zk-Rollup générique compatible EVM. [4]
zk-Sync v2.0
zk-Sync v2.0 n'est que l'un des nombreux projets actuellement en cours de développement d'un zk-EVM (d'autres incluent StarkNet, Polygon Hermez et Scroll). Contrairement à zk-Sync v1.0, qui obligeait les utilisateurs à reconstruire de grandes sections de leurs bases de code pour les transférer de l'EVM vers zk-Sync, dans zk-Sync v2.0, les programmeurs peuvent déployer leurs applications avec peu ou pas de modifications - ou comme zk-Sync aimerait le prétendre.
En pratique, tous les zk-EVM ne sont pas créés égaux. Il existe un compromis distinct entre la composabilité (à quel point elle est proche des contrats EVM d'origine) et les performances (à quelle vitesse les zk-Rollups s'exécuteront) [6]. Dans le cadre de ce compromis, zk-Sync a choisi d'optimiser complètement les performances, sacrifiant ainsi la composabilité.
Du point de vue de Vitalik Buterin, il existe quatre types distincts de zk-EVM, résumés dans le tableau suivant :
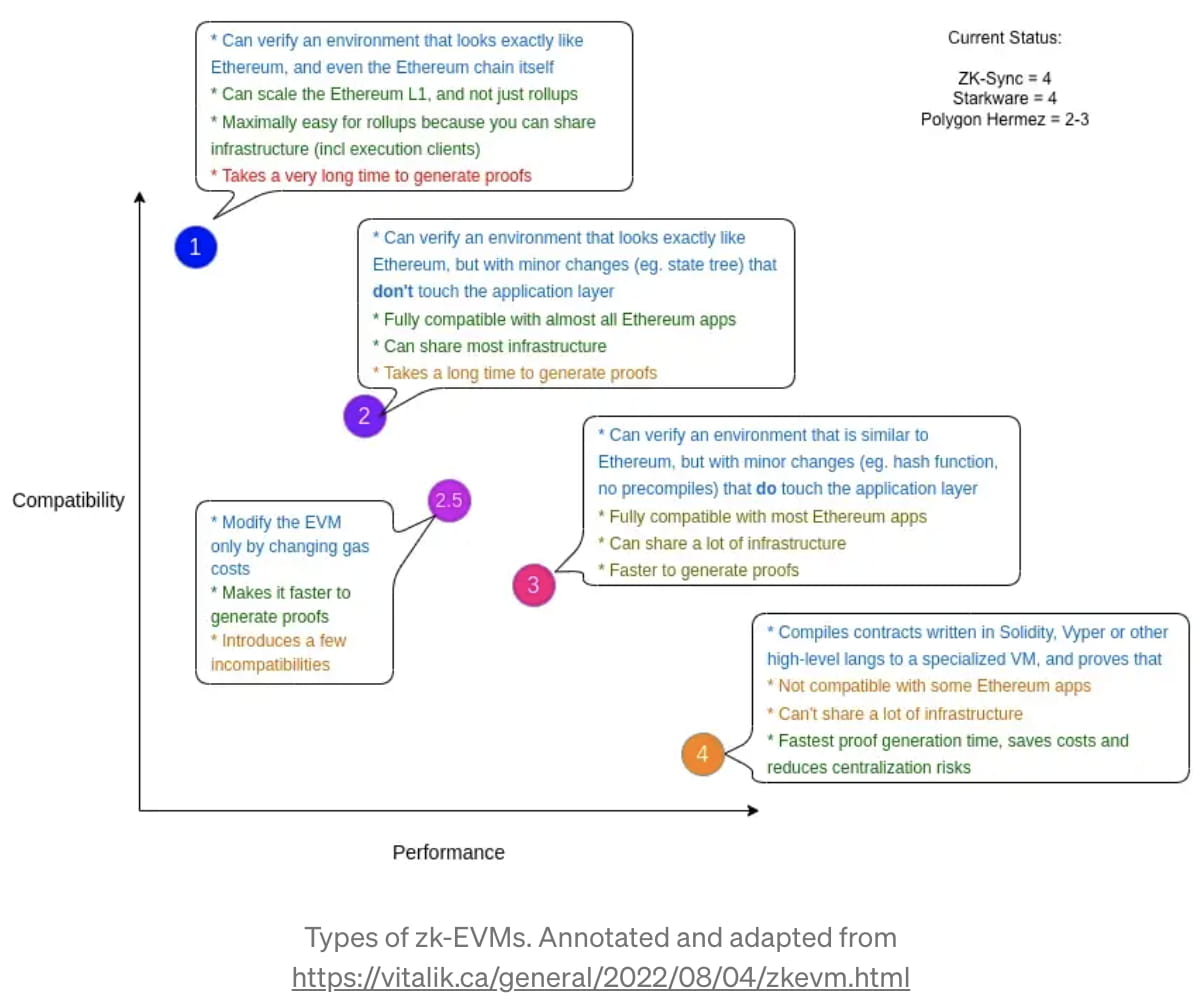
Comme l'indique Vitalik, dans son état actuel, zk-Sync v2.0 est un zk-EVM de type 4, capable de compiler des contrats écrits en Solidity et dans des langages de haut niveau en utilisant son propre compilateur, distinct de l'EVM. Étant donné que zk-Sync a un contrôle total sur la conception de son compilateur, ils sont capables d'optimiser de manière agressive la vitesse et le débit. Le coût est que certaines chaînes d'outils de débogage DApps et EVM peuvent être incompatibles avec zk-Sync v2.0. Essentiellement, zk-Sync est la même coque de voiture qu'Ethereum mais avec un moteur remplacé [5].
En effet, dans sa documentation pour les développeurs, Matter Labs affirme que si les opérations de « lecture » de contrats intelligents peuvent être intégrées sans aucune modification du code, les opérations d'« écriture » de contrats intelligents nécessitent un « code supplémentaire » en raison des « différences fondamentales entre L1 et L2 » [6] . En fait, c’est légèrement trompeur. Ce n'est pas tant dû à une « différence fondamentale » entre L1 et L2, mais plus encore à cause du type de zk-Rollup que Matter Labs a décidé de poursuivre : le cumul de type 4. Étant donné que zk-Sync est fondamentalement un cumul de type 4 qui utilise un compilateur et un bytecode différents, cela signifie que les contrats intelligents ont des adresses différentes et que l'infrastructure du débogueur qui s'appuie sur l'analyse du bytecode peut ne pas être en mesure de fonctionner sur zk-Sync v2. 0 [7].
À l'avenir, zk-Sync pourrait ajouter une prise en charge plus native du byte-code EVM, permettant au système de passer lentement à un cumul de type 3 prenant en charge un plus large éventail de ces « cas extrêmes ». Mais pour que le zk-Rollup de type 4 ou de type 3 de zk-Sync réussisse par rapport au rollup de type 2 de Polygon Hermez et Scroll Labs, qui échange essentiellement la vitesse contre une compatibilité plus large, il doit y avoir deux conditions préalables importantes. Premièrement, il n'y a qu'une infime fraction de projets sans importance qui sont incompatibles avec le compilateur personnalisé de zk-Sync. Deuxièmement, il existe une différence qualitative dans la vitesse d'exécution de zk-Sync par rapport à un zk-EVM de type 2.
Malheureusement, je pense personnellement que cela est peu probable. Tout écosystème de développement avancé repose sur une infrastructure « d’échafaudage » mature, comprenant des outils de débogage et de test pratiques et modularisés. Si, comme le postule Vitalik, une grande partie des outils de débogage natifs EVM ne pourront pas être portés sur zk-Sync en raison de différences de bytecode, alors zk-Sync devra développer sa propre suite d'outils de test et de débogage. Il s'agit d'une surcharge supplémentaire qui pourrait à terme entraver la vitesse d'adoption de zk-Sync en tant que solution L2, par rapport à ses concurrents zk-EVM de type 2 plus composables tels que Polygon Hermez et Scroll.
L'avenir des zk-Rollups
Avec de nombreux acteurs compétitifs dans la bataille pour les zk-EVM, ce n'est sans doute qu'une question de temps avant de voir un zk-EVM entièrement fonctionnel. Mais quelle est la prochaine étape ? Une route n’est utile que tant qu’elle comporte des bâtiments ; la force à long terme d'un zk-Rollup vient des projets utilisant cette solution.
À l'heure actuelle, DeFi, GameFi et les applications mobiles sont les principaux bénéficiaires de l'infrastructure zk-Rollup. DeFi et GameFi sont fondamentalement des économies d’échelle, car ils prospèrent dans un environnement où de nombreuses personnes les utilisent. Les applications mobiles telles que les portefeuilles mobiles ouvrent également les vannes au consommateur de masse qui est trop paresseux (ou ne peut pas se permettre) un ordinateur de bureau. Utiliser zk-Rollups pour ces situations a donc beaucoup de sens.
Mais ce n'est en aucun cas la limite de l'utilité de zk-Rollups. Au contraire, ce n’est que le début. Les zk-Rollups sont à Ethereum ce que la 5G est à Internet. Tout comme la 5G peut permettre un nouveau monde d'applications et de systèmes IoT, les zk-Rollups peuvent également ouvrir les vannes d'une « chaîne de blocs d'objets », permettant aux appareils numériques de notre monde physique (réfrigérateurs, montres, feux de circulation, etc.) d'être utilisés. intégré aux contrats intelligents sécurisés sur Ethereum.
L’un des principaux arguments contre l’IoT est qu’il permettra aux Big Tech de s’immiscer dans notre vie quotidienne. Mais avec une « Blockchain of Things », nous pouvons profiter des commodités de l’IoT sans nous soucier de la compromission de nos appareils intelligents sur une base de données centralisée. Au lieu de la commodité OU de la confidentialité, nous pouvons avoir la commodité ET la confidentialité. C'est le monde que zk-Rollups peut nous promettre.
🐦 @0xfishylosopher
📅 31 octobre 2022
Ces informations sont purement éducatives et ne doivent pas être considérées comme des conseils financiers. Tous les points de vue exprimés sont ceux de l’auteur et ne sont pas nécessairement approuvés par Web3.com Ventures.
Les références
[1] https://blog.matter-labs.io/baby-alpha-has-arrived-5b10798bc623
[2] Adapté de https://pages.cs.wisc.edu/~mkowalcz/628.pdf
[3] https://vitalik.ca/general/2021/01/05/rollup.html
[4] https://www.coindesk.com/tech/2022/07/20/the-sudden-rise-of-evm-compatible-zk-rollups/
[5] https://cryptobriefing.com/the-race-scale-ethereum-zkevm-rollups/
[6] https://docs.zksync.io/dev/contracts/#porting-smart-contracts
[7] https://vitalik.ca/general/2022/08/04/zkevm.html