Maggie@Foresight Ventures

Wichtige Erkenntnisse
Um eine vollständige Dezentralisierung in Web3-Anwendungen zu erreichen, benötigen wir technologische Fortschritte in vier Bereichen, darunter Datenverfügbarkeit (Blockchain-Skalierbarkeit), dezentrale Dateisysteme, dezentrale Datenbanken und dezentrales Computing.
Die Geschwindigkeit des Datenabrufs, das Anreizmodell und die Tokenomics sowie der Garantiealgorithmus für die Datenverfügbarkeit sind Schlüsselfaktoren, die bestimmen, ob ein Datei-/Datenbankspeicherprotokoll breite Anwendung findet oder nicht.
Der Schwerpunkt bei der Verbesserung dezentraler Dateisysteme und Datenbankprotokolle liegt auf der Verkürzung der Abrufzeiten.
Die Datenverfügbarkeitsschicht ist eine vielversprechende und wichtige Methode zur Skalierung der Blockchain. Die Technologie von Celestia muss noch auf dem Markt validiert werden, und ETH und Celestia könnten in Zukunft technisch zusammenwachsen.
App-Architekturen von Web2- und Web3-Anwendungen.
Im Vergleich zu Web2-Anwendungen, die oft aus einem Frontend, einem Backend und einer Datenebene mit Datenbank und Dateisystem bestehen, können Web3-DApps einfacher sein, da sie nur ein Frontend und einen Smart Contract benötigen, der sowohl als Backend als auch als Datenbank dient.
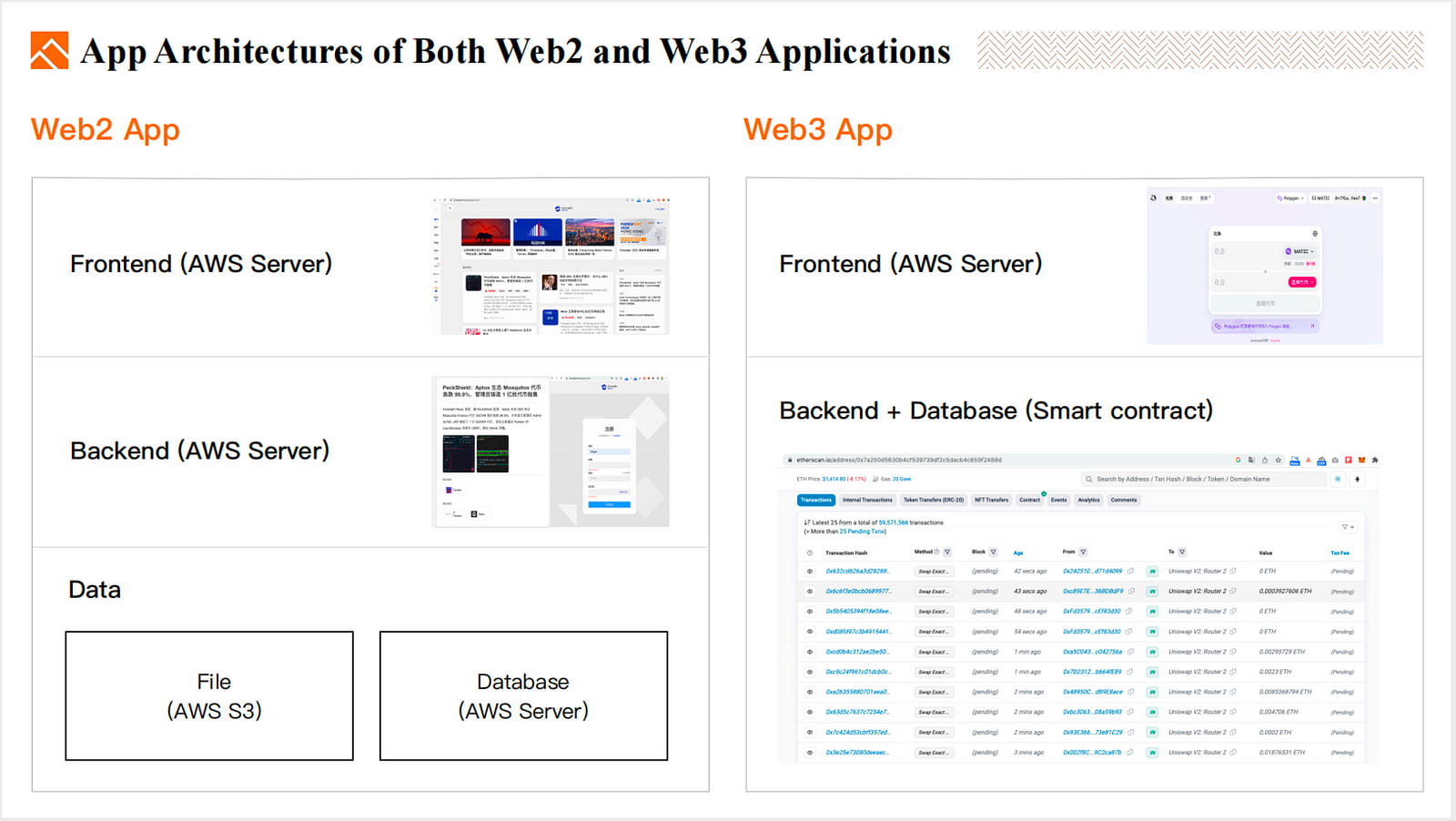
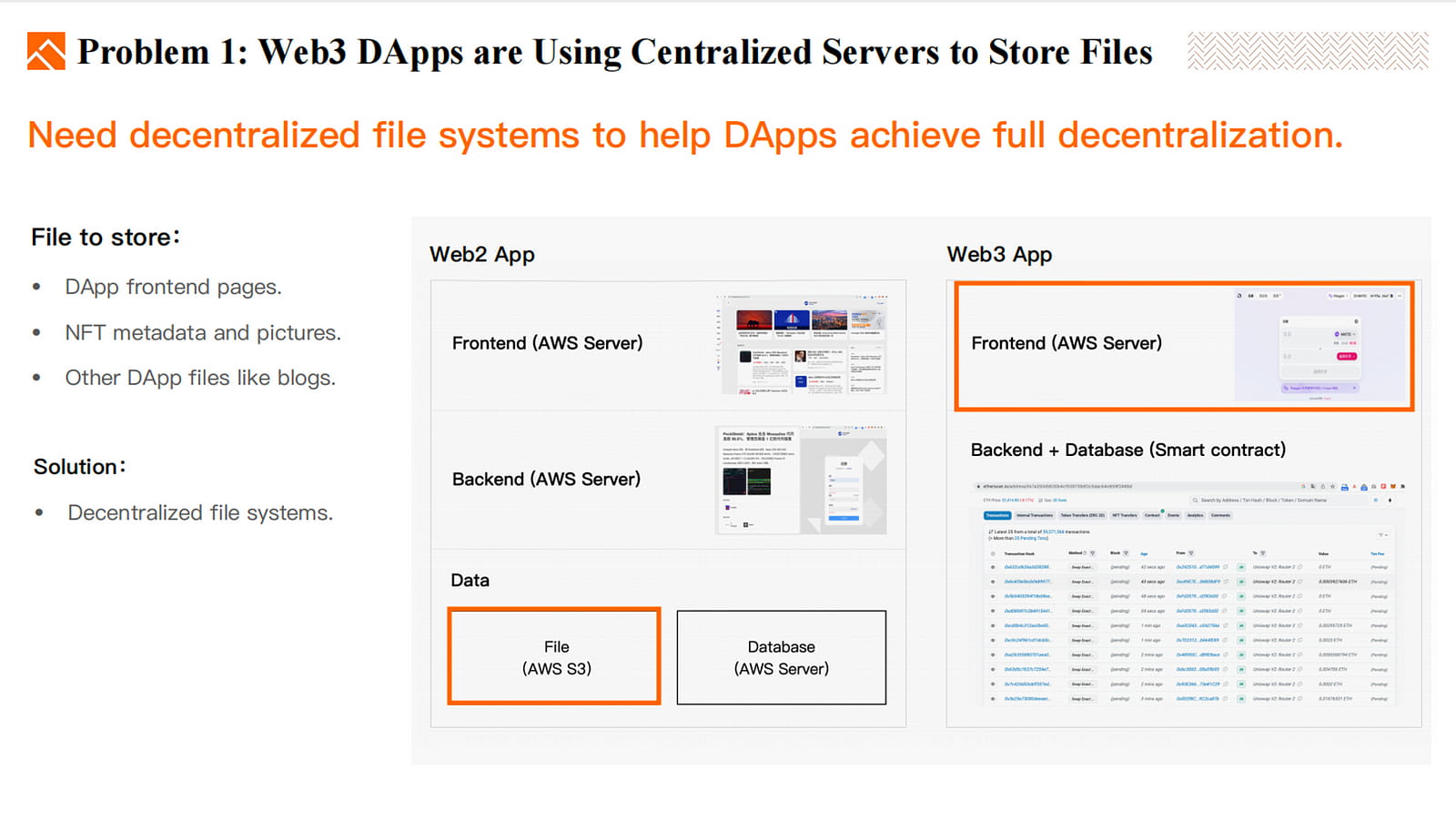
Da diesen DApps jedoch ein Dateisystem zum Speichern von Dateien fehlt, werden ihre Frontend-Seiten, Bilder und andere Dateien weiterhin auf zentralen Servern gehostet. Um eine vollständige Dezentralisierung zu erreichen, verwenden Entwickler jetzt dezentrale Dateisysteme, um die erforderlichen Dateien, einschließlich Frontend-Seiten, NFT-Metadaten und Bilder, für DApps zu speichern.
Um die strukturierte Datenspeicherung und die Backend-Computing-Kapazitäten zu verbessern, nutzen wir Datenverfügbarkeitstechnologie, um Blockchain zu skalieren. Darüber hinaus sind zwei Arten von Produkten entstanden: dezentrale Datenbanken und dezentrales Computing.
Durch die Nutzung von Blockchain können Entwickler Finanzdaten und andere wichtige Informationen im Zusammenhang mit DApps speichern. Andererseits können dezentrale Datenbanken zum Speichern strukturierter Daten wie NFT-Metadaten, DAO-Abstimmungsdaten, DEX-Auftragsbücher, soziale Daten usw. verwendet werden. Darüber hinaus kann dezentrales Computing bei der Skalierung des Backends helfen.

Insgesamt sind zum Erstellen vollständig dezentralisierter, flexibler und umfangreicher Web3-DApps vier Arten von Produkten und technologischen Fortschritten erforderlich.
Dezentrales Dateisystem: Speichern Sie DApp-Frontend-Webseiten, NFT-Bilder, Videos und andere Dateien von Dapps.
Dezentrale Datenbank: Speichern Sie strukturierte Daten wie NFT-Metadaten, DAO-Stimmen und DEX-Orderbuch.
Datenverfügbarkeit: Skalieren Sie die Blockchain und speichern Sie finanzielle und wichtige Daten für DApps.
Dezentrale Computertools: Skalieren Sie das Backend von DApps.

1. Dezentrales Dateisystem
Dezentraler Dateispeicher dient als Ersatz für zentralen Speicher und erleichtert die Realisierung serverloser DApps. Die Nachfrage nach DApps für dezentrale Dateisysteme wächst und wird ein wichtiger Bestandteil des Web3-Technologie-Stacks sein.
Die Hauptvorteile der dezentralen Speicherung im Vergleich zur Verwendung einer zentralen Speicherung liegen in der Beseitigung vertrauenswürdiger Drittparteien, erhöhter Redundanz, Beseitigung einzelner Ausfallpunkte und geringeren Kosten.
Laut Messaris Statistik betrug die Marktkapitalisierung der vier wichtigsten dezentralen Dateispeicherprotokolle fast 1,6 Milliarden US-Dollar, ein Rückgang von 83 % gegenüber den 9,4 Milliarden US-Dollar. Die Gesamtspeicherkapazität betrug über 17 Millionen Terabyte (TB), ein Anstieg von 2 % gegenüber dem Vorjahr, und der genutzte Speicher betrug 532.500 TB, ein Anstieg von 1280 % gegenüber dem Vorjahr.

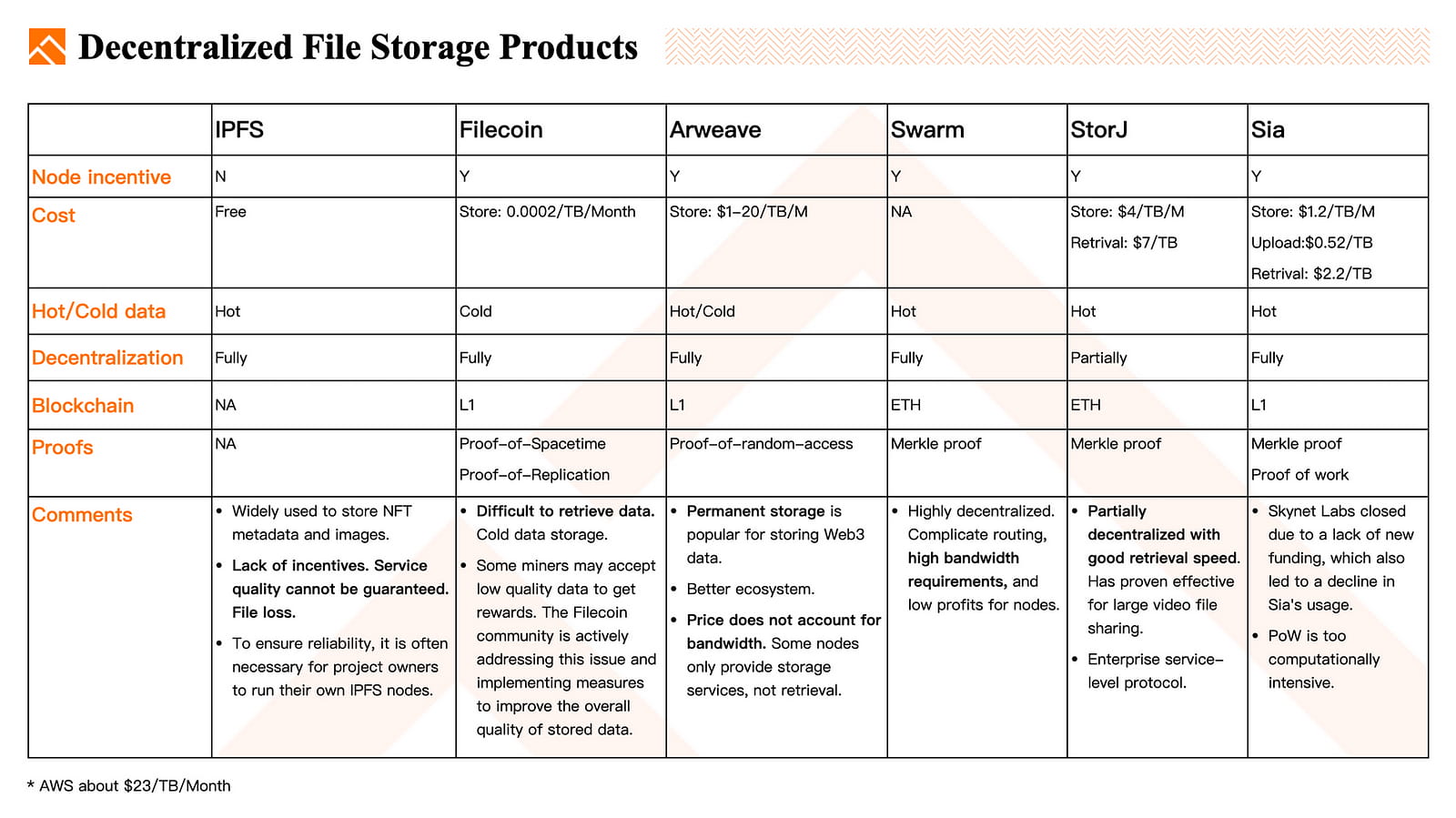
Werfen wir einen Blick auf die aktuelle Situation mehrerer beliebter dezentraler Speicherprojekte. Die Datenspeicherung mit all diesen dezentralen Speicherprotokollen ist im Vergleich zu AWS deutlich günstiger. Während AWS etwa 23 USD/TB/Monat berechnet, liegen die Kosten für diese dezentralen Speicherprotokolle zwischen 0,0002 und 20 USD/TB/Monat.
IPFS: IPFS ist derzeit das am weitesten verbreitete Protokoll zum Speichern von Bildern und Metadaten für NFTs. Es eignet sich hervorragend zum Speichern häufig abgerufener oder „heißer“ Daten. Allerdings verfügt IPFS nicht über integrierte Möglichkeiten, um die Speicherung zu belohnen, nachzuweisen, dass Daten korrekt gespeichert sind, oder eine Einigung zwischen den Teilnehmern herzustellen, wie dies bei Blockchains der Fall ist. Das bedeutet, dass das Risiko eines Datenverlusts besteht, wenn diese nur auf IPFS gespeichert sind. Beispielsweise löscht der IPFS-Dienst von Infura Daten, auf die seit sechs Monaten nicht zugegriffen wurde. Wenn Sie Ihre Daten also für lange Zeit verfügbar halten möchten, betreiben Sie am besten Ihren eigenen IPFS-Knoten.
Filecoin: Filecoin bietet niedrige Speicherkosten und wird hauptsächlich zum Speichern „kalter“ Daten wie Archivdaten verwendet. Filecoin verfügt nicht über einen integrierten Gebührenmechanismus für den Datenabruf. Einige Miner akzeptieren Daten von geringer Qualität, um Belohnungen zu erhalten, weigern sich jedoch, den Datenabruf zu ermöglichen. Die Filecoin-Community befasst sich aktiv mit diesem Problem und setzt Maßnahmen zur Verbesserung der Gesamtqualität der gespeicherten Daten um.
Arweave: Arweaves Idee der permanenten Speicherung ist für die Speicherung von DApp-Daten willkommen. Das Ökosystem entwickelt sich gut, es gibt dezentrale Datenbanksysteme, die Arweave zum Speichern von Datenbankdateien verwenden, sowie Skalierbarkeitslösungen der zweiten Ebene, die auf Arweave basieren. Bei Arweave berücksichtigt der Preis nicht die Bandbreite, einige Knoten bieten nur Speicherdienste, keinen Abruf.
Swarm: Sowohl für die Speicherung als auch für den Abruf in Swarm fallen Bandbreitengebühren an. Das System ist stark dezentralisiert und hat hohe Bandbreitenanforderungen für Knoten.
StorJ: StorJ unterscheidet sich von anderen Protokollen, es ist teilweise dezentralisiert und hat eine gute Abrufgeschwindigkeit. Hat sich für den Austausch großer Videodateien als effektiv erwiesen.
Sia: Skynet Labs wurde aufgrund fehlender neuer Finanzierung geschlossen, was auch zu einem Rückgang der Nutzung von Sia führte.
Wir bewerten die Benutzerfreundlichkeit eines dezentralen Dateispeicherprotokolls hauptsächlich anhand von drei Faktoren:
Geschwindigkeit des Datenabrufs. Sie ist von entscheidender Bedeutung, da sie die Effizienz eines Speichersystems bei der Beantwortung von Anfragen von DApps bestimmt und sich direkt auf die Benutzererfahrung von DApps auswirkt. Zu den Faktoren, die die Geschwindigkeit des Datenabrufs beeinflussen können, gehören: ob für Datenabfragen eine Gebühr anfällt, der Grad der Dezentralisierung von Knoten, die Knotenqualität, die Datenweiterleitungslogik und Einrichtungen wie CDNs für beschleunigte Abfragen.
Anreizmodell und Tokenökonomie. Anreizmodelle und Tokenökonomie wirken sich auf die Teilnahme von Speicherknoten aus und beeinflussen ihr Verhalten. Derzeit besteht das gängige Preismodell aus Speichergebühren plus Bandbreitengebühren, was bedeutet, dass Benutzer eine Speichergebühr zahlen müssen, wenn sie Daten speichern, und eine Bandbreitengebühr, wenn sie darauf zugreifen. Wenn Datenabfragen kostenlos sind, fehlt den Knoten oft die Motivation, sie bereitzustellen. Darüber hinaus wirken sich Anreizmodelle und Tokenökonomie auf die Einnahmen der Miner aus, was sich auf die Anzahl der Knoten und die Speicherkapazität der Dienste auswirken kann.
Algorithmus zur Datenverfügbarkeitsgarantie. Dies ist ein Algorithmus, der in dezentralen Netzwerken verwendet wird, um die kontinuierliche Verfügbarkeit von Daten und die ordnungsgemäße Bereitstellung von Diensten durch Knoten sicherzustellen. Derzeit ist der Proof of Random Access die am weitesten verbreitete Methode.

Insgesamt sind wir der Meinung, dass
Die Produkte und Dienste, die dezentrale Speicherprotokolle nutzen, befinden sich noch in der Anfangsphase.
Der Schwerpunkt bei der Verbesserung der Speicherprotokolle liegt auf der Verkürzung der Abrufzeiten.
Die Geschwindigkeit des Datenabrufs, das Anreizmodell und die Tokenomics sowie der Garantiealgorithmus für die Datenverfügbarkeit sind Schlüsselfaktoren, die bestimmen, ob ein Protokoll breite Anwendung findet oder nicht.

2. Dezentrale Datenbank
Datenbanken werden in Anwendungen häufig verwendet. Dezentrale Datenbanken sind eine entscheidende Technologie, um eine vollständige Dezentralisierung in DApps zu erreichen.
Dezentrale Datenbanken können zentralisierte Datenbanken ersetzen, um strukturierte Hot Data zu speichern, die DApps benötigen, wie z. B. NFT-Metadaten, DAO-Abstimmungen, DEX-Auftragsbücher, Social-Media-Daten usw.
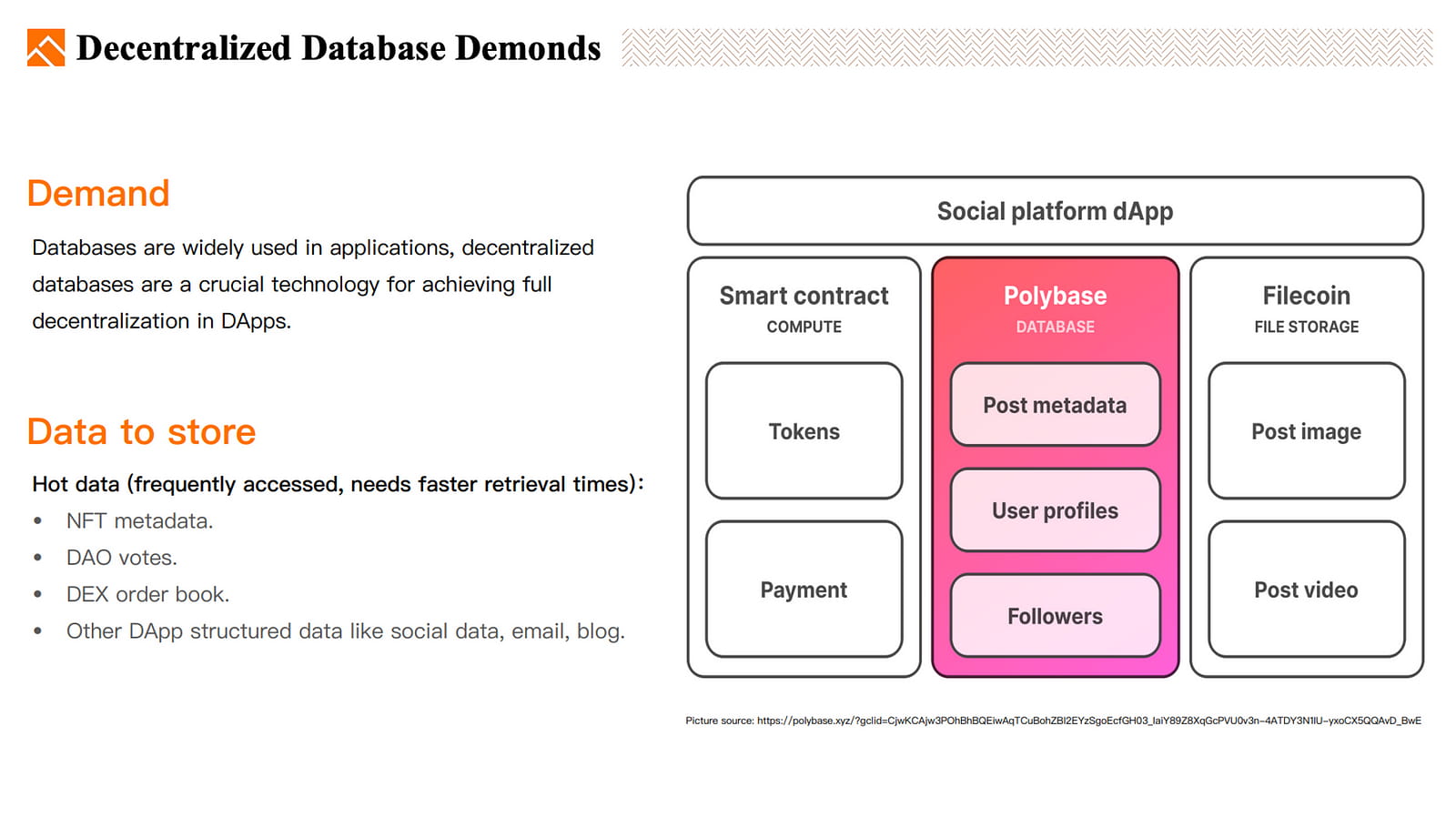
Es gibt viele dezentrale Datenbankprojekte, insbesondere in den letzten zwei Jahren sind mehrere innovative Projekte entstanden.
Ceramic: Ceramic ist ein 2019 gestartetes Projekt. Daten werden in Stream-Einheiten gespeichert und verwaltet, und formatierte Ereignisprotokolle werden den Streams hinzugefügt. Das Protokoll wird in eine Datei umgewandelt und auf IPFS hochgeladen. Bietet GraphQL-API-Abfragen. Ceramic hat kein Anreizmodell wie IPFS und unterstützt das Erstellen, Lesen und Aktualisieren von Daten (CRU).
OrbitDB: OrbitDB ist ein früheres Projekt im Vergleich zu Ceramic, das ebenfalls das IPFS-Dateisystem zur Dateispeicherung verwendet. Es unterstützt die Speicherung sowohl von NoSQL-Datenbanken als auch von Dateien.
Tableland: Das Projekt startete 2022 und befindet sich derzeit in der öffentlichen Testphase. Die Produktionsversion von Tableland wird 2023 veröffentlicht. Die Datenspeicherung erfordert die Verwendung von Smart Contracts, die SQL-Anweisungen definieren und Nutzungsberechtigungen festlegen. Das Lesen der Daten erfolgt außerhalb der Kette und erfordert keine Zahlung. Derzeit wurde der Vertrag auf L2s wie ETH und OP eingesetzt.
Polybase: Das Projekt ist jetzt im Testnetzwerk live. Es handelt sich um eine NoSQL-Datenbank, die CRUD-Operationen unterstützt, wobei für jede Operation Gebühren anfallen. Darüber hinaus bietet Polybase Unterstützung für verschiedene Dateisysteme zum Speichern von Datenbankdateien, darunter lokale Festplatten, IPFS, Filecoin, Polystore und sogar AWS S3. Polybase nutzt auch Zahlungskanäle für Zahlungen per Datenabfrage, wodurch die Häufigkeit von On-Chain-Transaktionen reduziert und durch Zahlungen verursachte Abfrageverzögerungen vermieden werden.
Web3Q: Auch bekannt als EthStorage. Projektstart 2022. Das Testnetz ist aktiv. Ein neues URL-Muster für das Web//Zugriffsprotokoll für den Datenzugriff wurde vorgeschlagen.
Kwill: Kwill ist ein auf Arweave basierendes SQL-Datenbanksystem, das Smart Contracts zur Zahlung verwendet.
KYVE: KYVE ist ein auf Arwave basierendes Datenbanksystem.
Aus technischer Sicht:
Sowohl SQL als auch NoSQL können als Datenbanken verwendet werden. Die Datenstruktur von SQL erfordert eine hohe Konsistenz und bietet eine stärkere Unterstützung für gemeinsame Abfragen, wodurch sie ausgereifter und effizienter wird. Das KV-Format von NoSQL ist besser für das Entwurfsmuster von Ethereum geeignet, unterstützt umfangreiche Datentypen und ist flexibel und leicht skalierbar.
In Bezug auf die Funktionalität ist die beste Option die Unterstützung von CRUD, aber die Unterstützung von UD erhöht die Komplexität des Systems. Wenn das System lokalen Speicher verwendet, werden Abfragen historischer Werte möglicherweise nicht unterstützt. Wenn Sie IPFS und Arweave als Dateisysteme verwenden, muss die Datenbank nur Anhänge unterstützen, da es sonst mehrere Versionen derselben Daten gibt, was die Speicherkosten verdoppelt.
Bei der Auswahl eines zugrunde liegenden Dateisystems gibt es zwei Möglichkeiten: 1) Speichern Sie Datenbankdateien in dezentralen Dateisystemen wie IPFS und Arweave; 2) Speichern Sie sie lokal auf Knoten oder in der S3-Cloud. Wenn ein dezentrales Datenbankprojekt eine angepasste Abruflogik oder Optimierung erfordert, ist die Verwendung von lokalem Speicher oder S3 ein flexiblerer Ansatz.
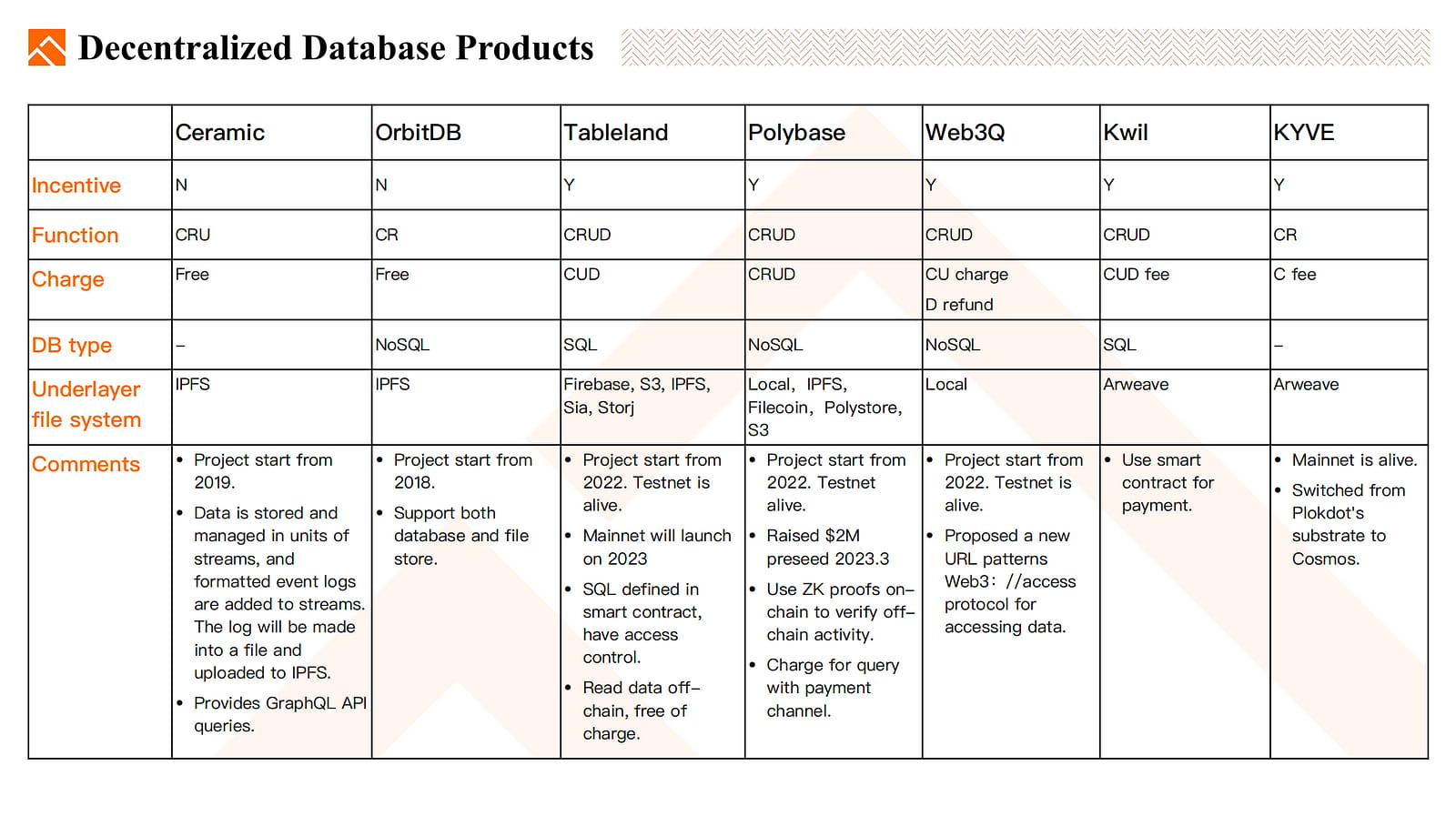
Insgesamt glauben wir, dass
Der Bereich der dezentralisierten Datenbanken verdient besondere Aufmerksamkeit, da hier ein dringender Bedarf besteht, es jedoch noch kein allgemein akzeptiertes und genutztes Produkt gibt.
Der Reifegrad dezentraler Datenbanken ist geringer als der dezentraler Dateispeichersysteme. Die dezentrale Datenbanktechnologie basiert auf dem dezentralen Dateisystem und viele Projekte werden im Jahr 2022 gestartet.
Der Hauptfokus bei der Verbesserung der Speicherprotokolle liegt auf der Verkürzung der Abrufzeiten. Die Geschwindigkeit des Datenabrufs, das Anreizmodell und die Tokenomik sowie der Garantiealgorithmus für die Datenverfügbarkeit sind Schlüsselfaktoren, die darüber entscheiden, ob ein Protokoll weit verbreitet ist oder nicht.

3. Datenverfügbarkeit
Das Konzept der Datenverfügbarkeit unterscheidet sich von dezentralen Dateisystemen und Datenbanken, wie auf den Websites von Ethereum und Celestia erläutert.
Ethereum: Datenverfügbarkeit ist die Garantie, dass der Blockvorschlaggeber alle Transaktionsdaten für einen Block veröffentlicht hat und dass die Transaktionsdaten anderen Netzwerkteilnehmern zur Verfügung stehen.
Celestia: Bei der Datenverfügbarkeit geht es darum, ob die im neuesten Block veröffentlichten Daten verfügbar sind.
Dezentrale Dateisysteme und Datenbanken stellen zwar in erster Linie die Verfügbarkeit der von Benutzern gespeicherten Daten sicher, befassen sich jedoch nicht speziell mit Transaktionsdaten.
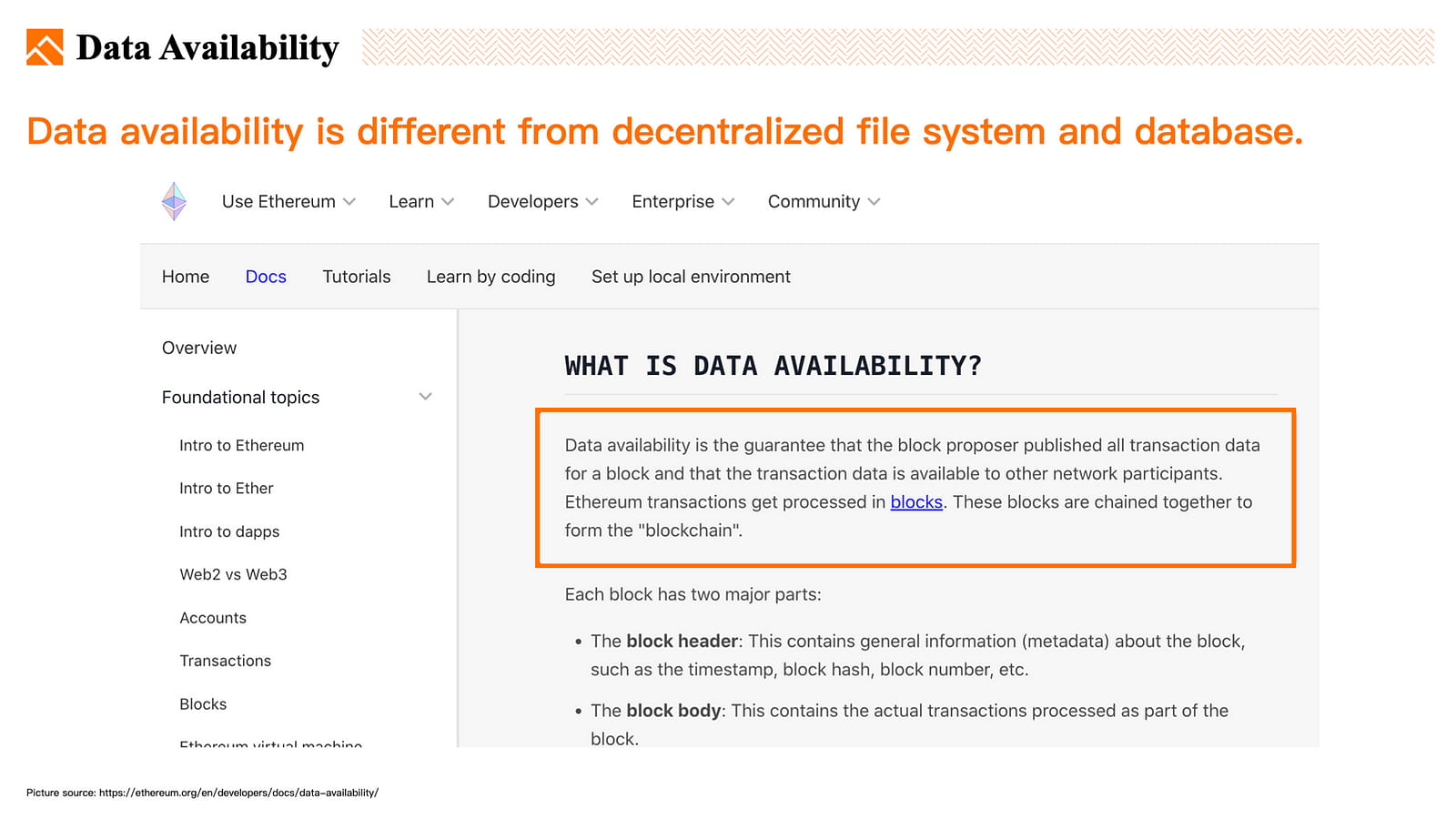
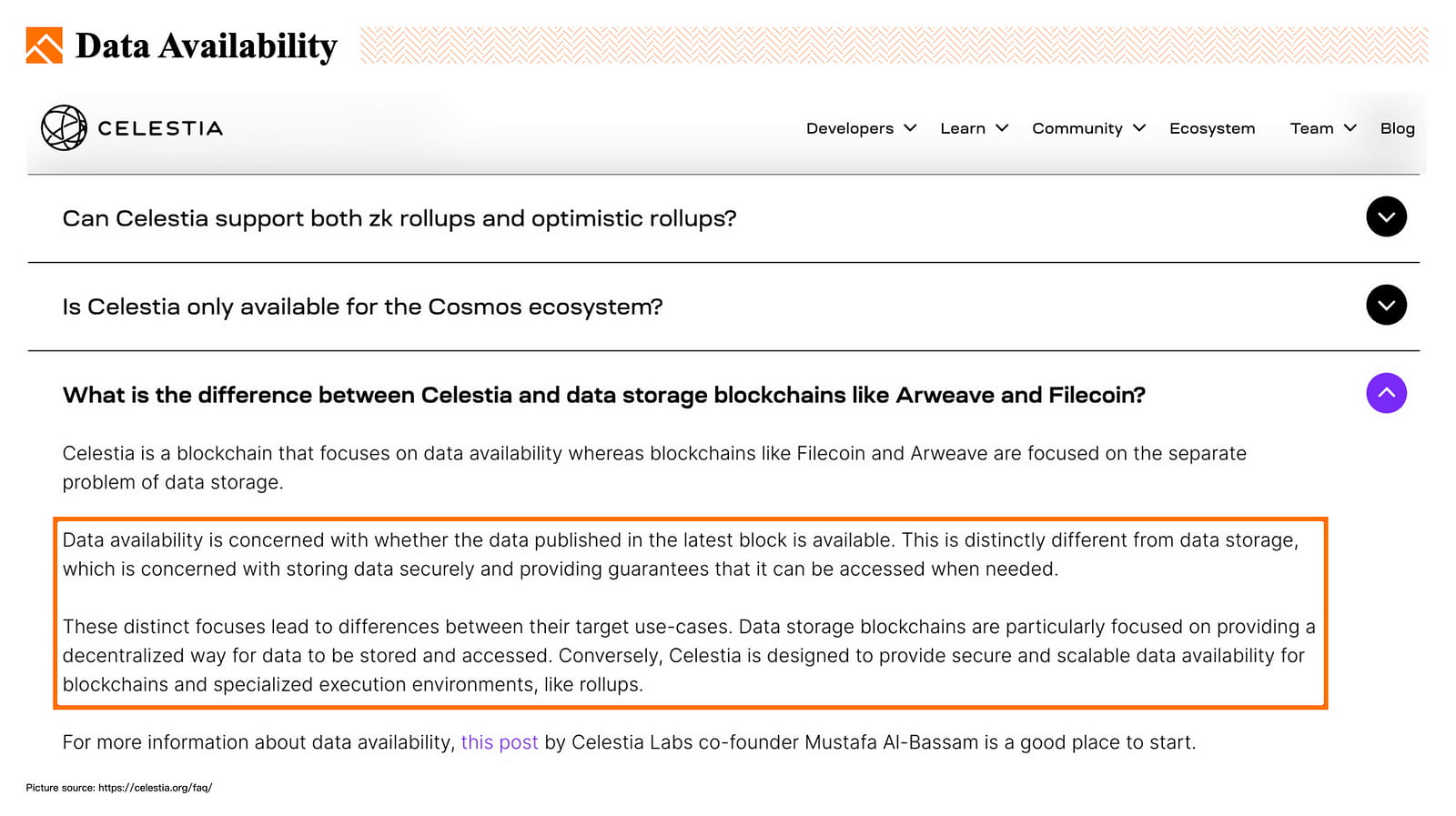
Derzeit gibt es mehrere Datenverfügbarkeitsprojekte, darunter:
Ethereum. ETH dient als DA-Schicht (Datenverfügbarkeit) für Layer 2-Rollup.
Celestia. Celestia ist eine speziell entwickelte DA-Schicht, die nur die Datenverfügbarkeit verwaltet und keine Transaktionen ausführt. Sie löste 2022 einen Trend zu modularen Blockchains aus.
EigenDA und andere DA-Produkte. Sicherstellung der Datenverfügbarkeit durch Ausschüsse.

Äther
ETH Layer 2 erstellt und übermittelt Stapel von Transaktionen an das Ethereum-Netzwerk und speichert die Daten in einem Ethereum-Smart-Contract auf Layer 1. Dadurch wird die garantierte Verfügbarkeit von L2-Transaktionsdaten über das ETH-Netzwerk gewährleistet.
Obwohl Rollups den Durchsatz von ETH durch Off-Chain-Berechnungen erhöhen können, ist ihre Kapazität durch den Datendurchsatz der L1-ETH-Blockchain begrenzt. Daher muss Ethereum seine Datenspeicher- und -verarbeitungskapazitäten erhöhen.
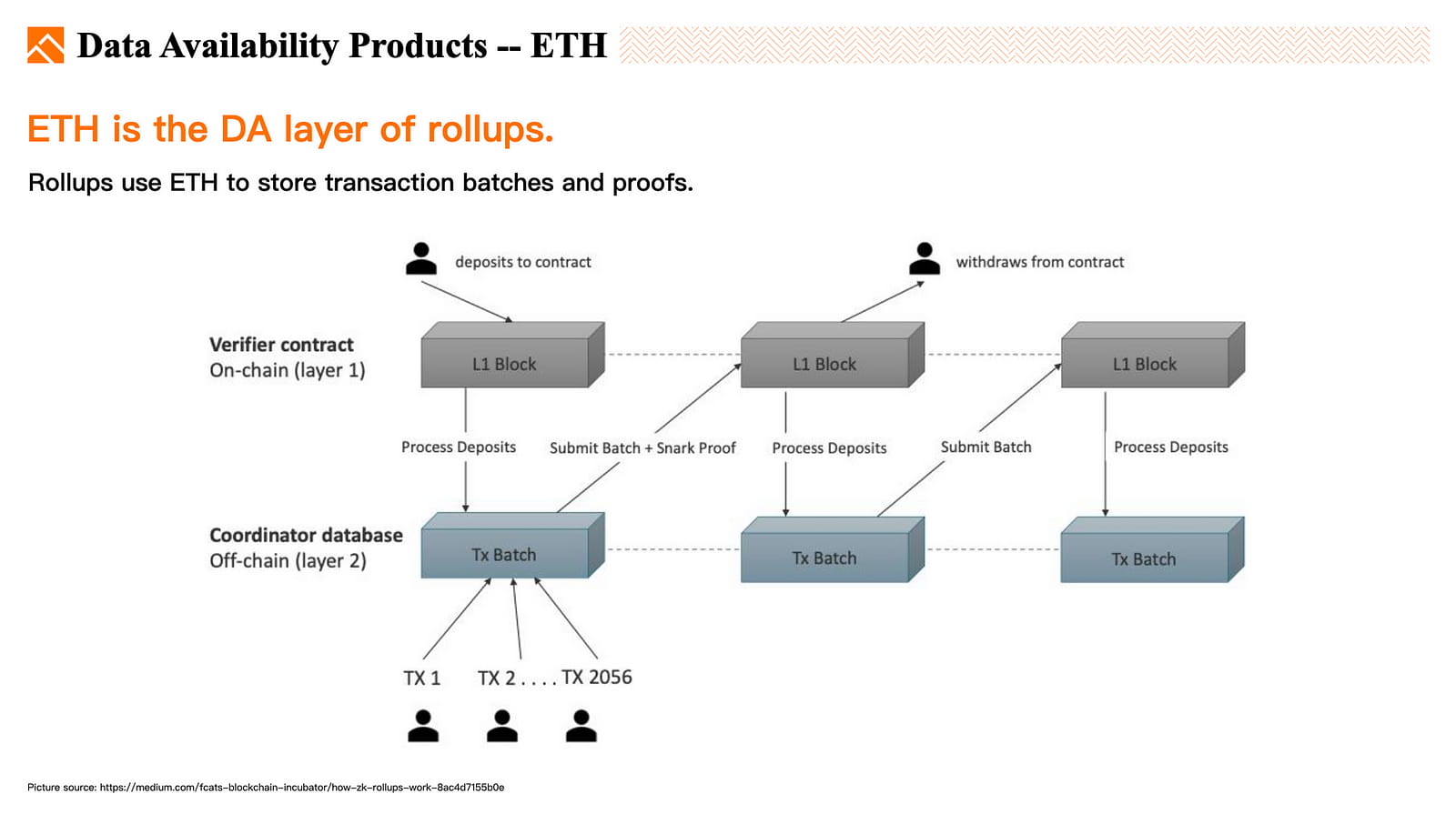
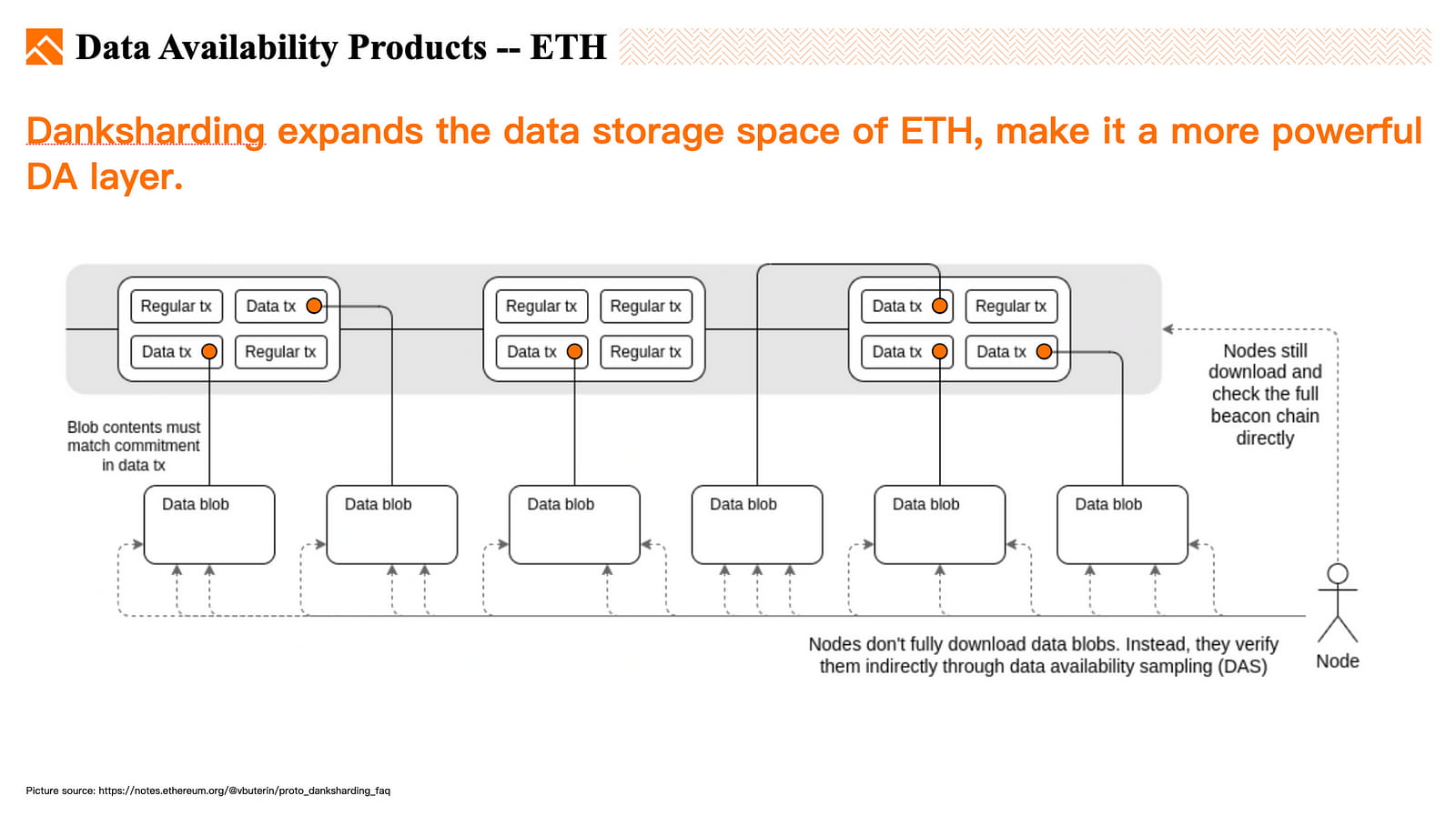
Um die DA-Kapazität von Ethereum zu erhöhen, wurde Danksharding in die Roadmap von ETH aufgenommen und gilt derzeit als eines der wichtigsten und dringendsten Updates.
Danksharding ist ein Sharding-Design, die Datenverfügbarkeit wird an jedes Shard delegiert und jeder Validierer muss nur einen vollständigen Knoten für sein eigenes Shard ausführen, während er andere Shards mit geringer Client-Kapazität ausführt.
Proto-danksharding (EIP-4844) ist eine vorläufige Implementierung von Dankshading, die voraussichtlich in der zweiten Hälfte des Jahres 2023 implementiert wird. Es führt einen außerhalb der Kette gespeicherten Datenblob ein, der über Transaktionen auf ETH gemountet wird, sowie vorkompilierten Code zur Validierung von Blob. Jeder Blob ist ungefähr 125 kB groß, während ein Block nur 90 kB groß ist. Derzeit können maximal acht Blobs pro Block gemountet werden, was zu einem zusätzlichen Speicherplatz von 1 MB führt. Bei Proto-danksharding wurden die Daten nicht geshardet, und Validierer müssen weiterhin alle Blob-Daten herunterladen und die Verfügbarkeit direkt überprüfen. Nach der Implementierung von EIP4844 kann Blob bei gleichem Gasverbrauch 10-mal mehr Daten speichern als Calldata. Die Daten von Rollup können in Zukunft in Blob gespeichert werden, wodurch die Transaktionsgebühren um eine Größenordnung reduziert werden. Nach der vollständigen Implementierung wird Danksharding noch günstiger.
Zusammenfassend kann Danksharding die Datenspeicherkapazität von Ethereum verbessern, die Kosten für als DA verwendete ETH senken und eine leistungsfähigere DA-Schicht werden.
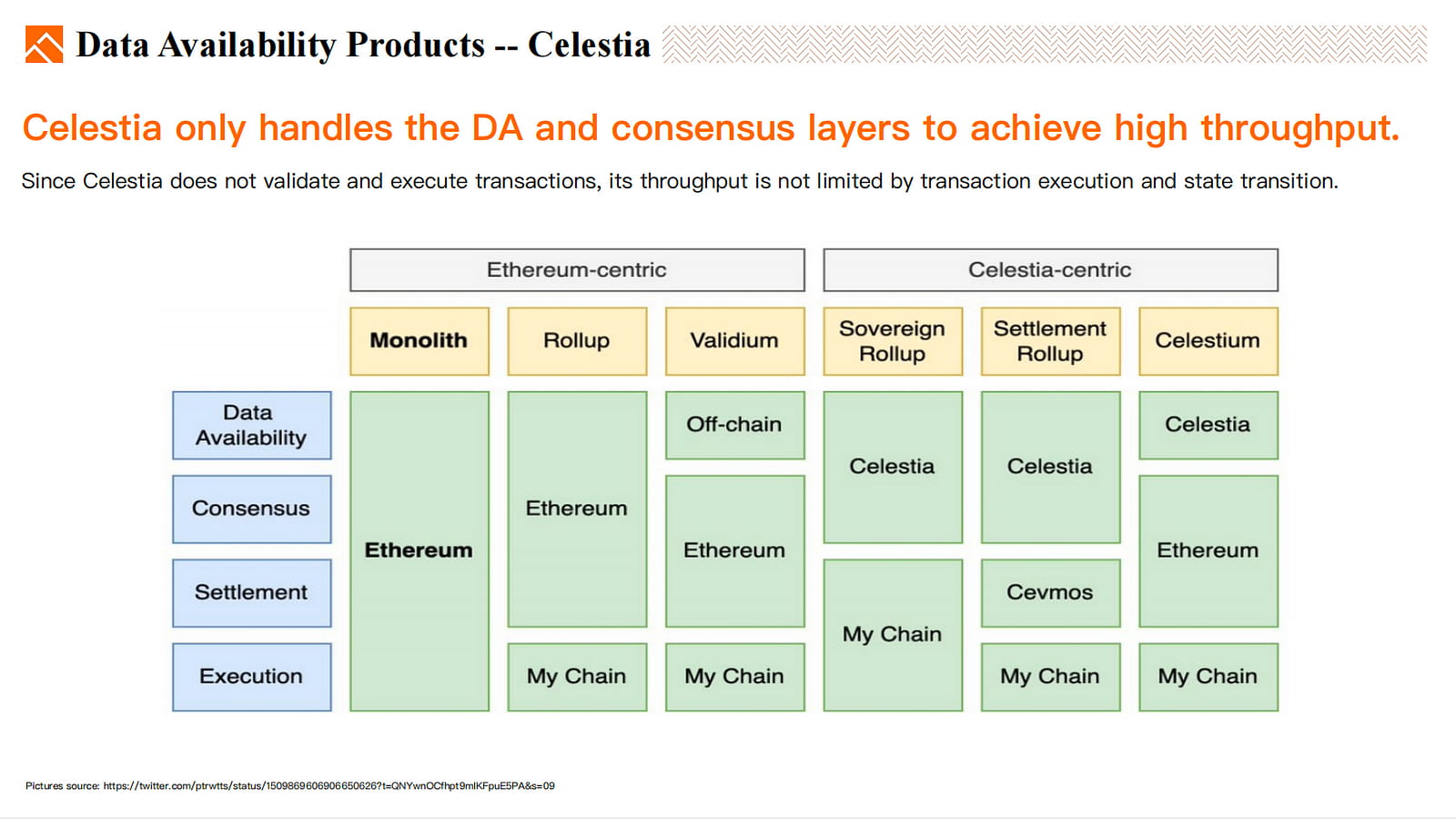
Celestia
Celestia ist eine minimale Blockchain, die Transaktionen nur anordnet und veröffentlicht, aber nicht ausführt. Durch die Entkopplung der Konsens- und Anwendungsausführungsebenen modularisiert Celestia den Blockchain-Technologie-Stack und eröffnet neue Möglichkeiten für dezentrale Anwendungsentwickler.
Celestia ist für die DA-Schicht verantwortlich, während ETH für Konsens und Abwicklung zuständig ist und die Anwendungskette für die Ausführung verantwortlich ist.
Celestia ist sowohl für die DA-Schicht als auch für die Konsensschicht verantwortlich, während Abwicklung und Ausführung von der Anwendungskette übernommen werden. Alternativ kann die Abwicklung Cevmos verwenden, wobei die Ausführung weiterhin in der Verantwortung der Anwendungskette liegt.
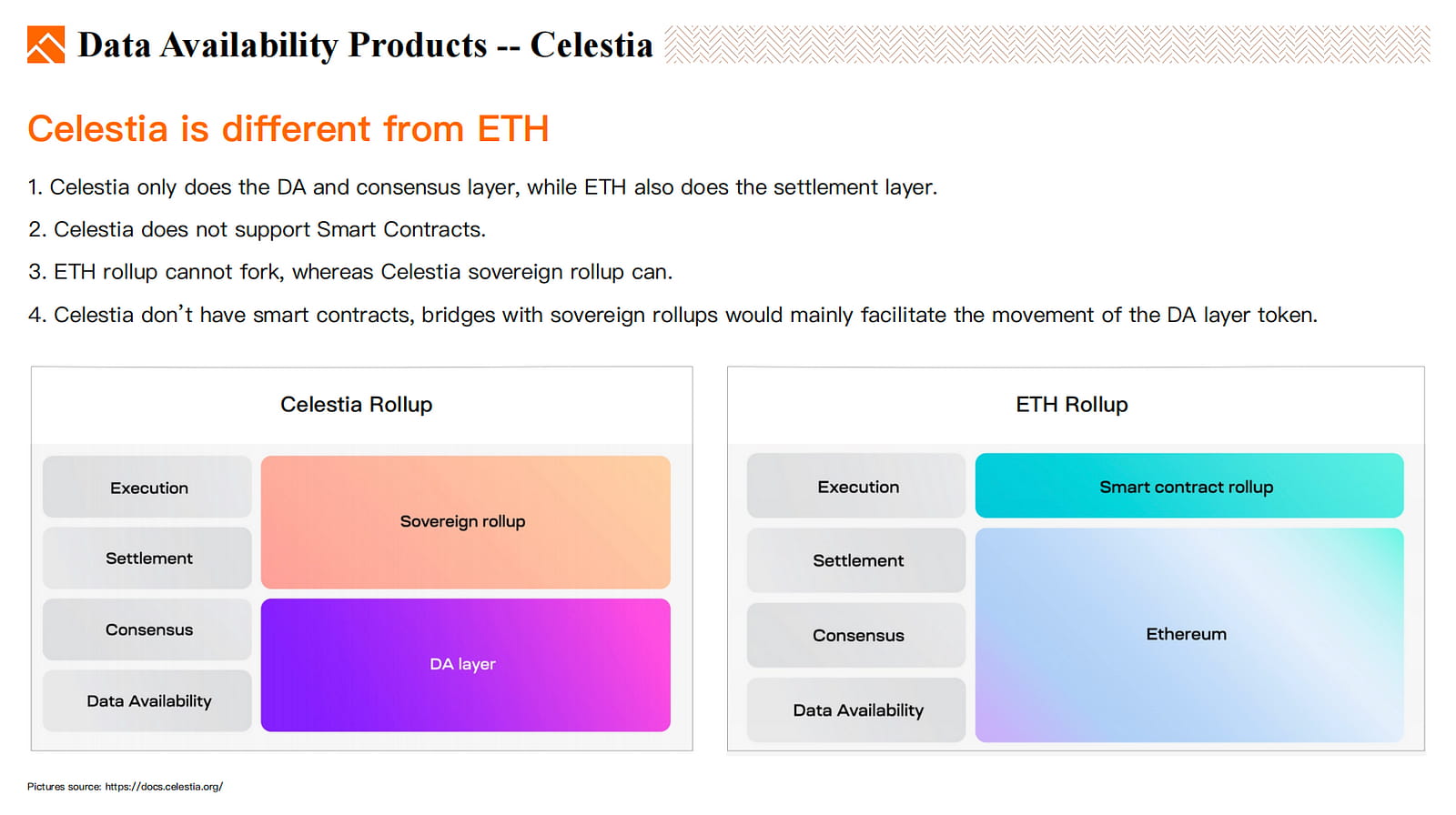
Celestia integriert ein zweidimensionales Reed-Solomon-Kodierungsschema und hat ein Zufallsstichprobenschema entwickelt, um die Verfügbarkeit von Daten zu überprüfen und sie wiederherzustellen, ähnlich der von ETH verwendeten Validierungsmethode.
Und Celestia weist auch erhebliche Unterschiede zu ETH auf.
Celestia konzentriert sich auf die DA-Schicht und die Konsensschicht, während ETH auch als Abwicklungsschicht für Rollups diente
Celestia verfügt nicht über eine Turing-vollständige virtuelle Smart-Contract-Maschine und unterstützt daher keine Smart Contracts.
Das souveräne Rollup von Celestia kann sich in mehrere Ketten aufspalten, das Rollup von ETH hingegen nicht.
Celestia hat keine Smart Contracts, Brücken mit souveränen Rollups würden hauptsächlich die Bewegung des DA-Layer-Tokens erleichtern.
Das Ökosystem von Celestia wächst schnell.
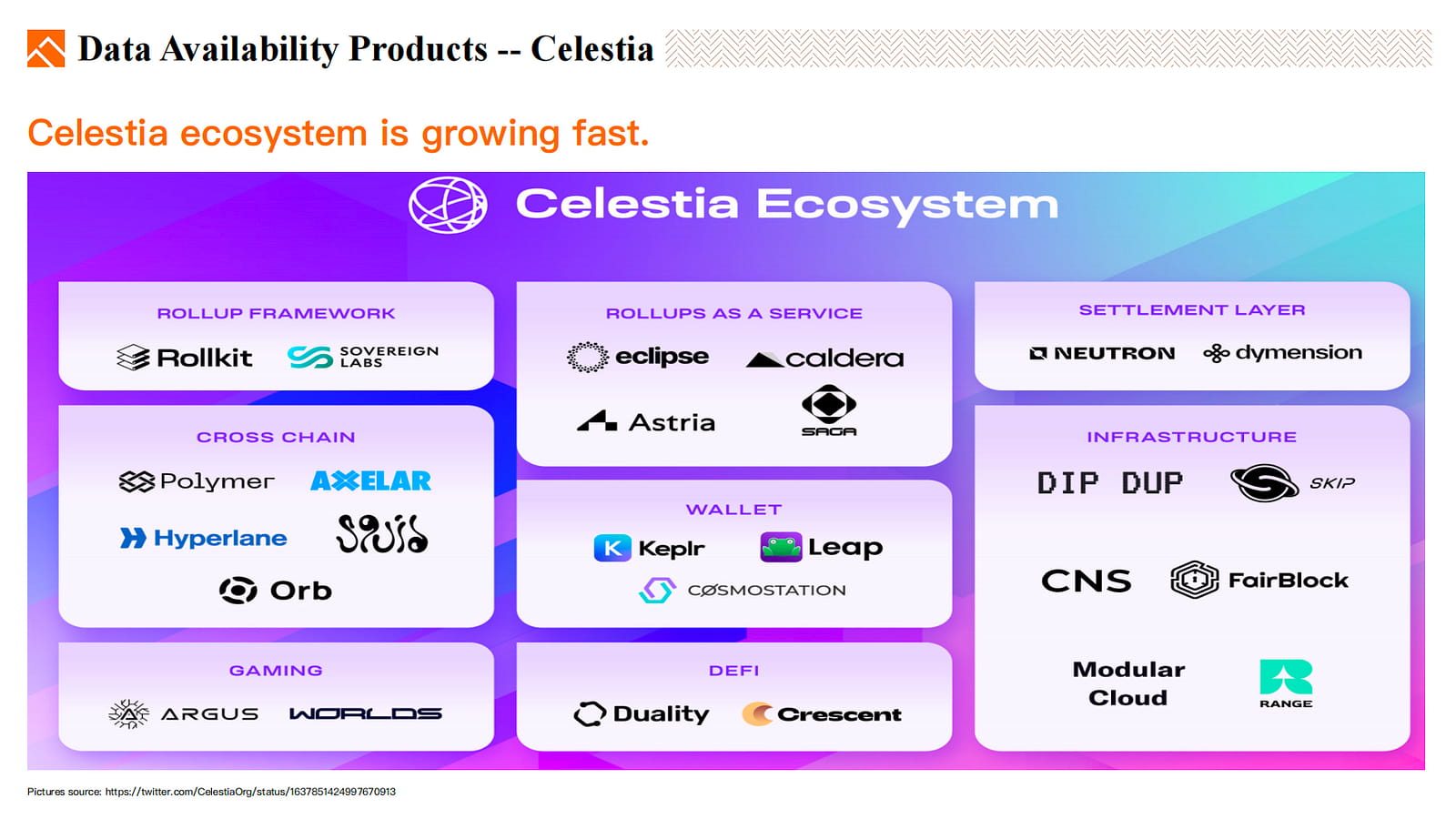
DA außerhalb der Kette
Off-Chain-DA umfasst hauptsächlich
Data Availability Committees (DACs) sind vertrauenswürdige Parteien, die die Datenverfügbarkeit sicherstellen oder bestätigen. DACs werden auch von einigen Validiums verwendet.
Proof-of-Stake Data Availability Committees sind deutlich sicherer als reguläre DACs, da sie ehrliches Verhalten direkt belohnen. Hier kann jeder zum Validator werden und Daten Off-Chain speichern. Allerdings muss er dafür eine „Anleihe“ stellen, die in einem Smart Contract hinterlegt wird.

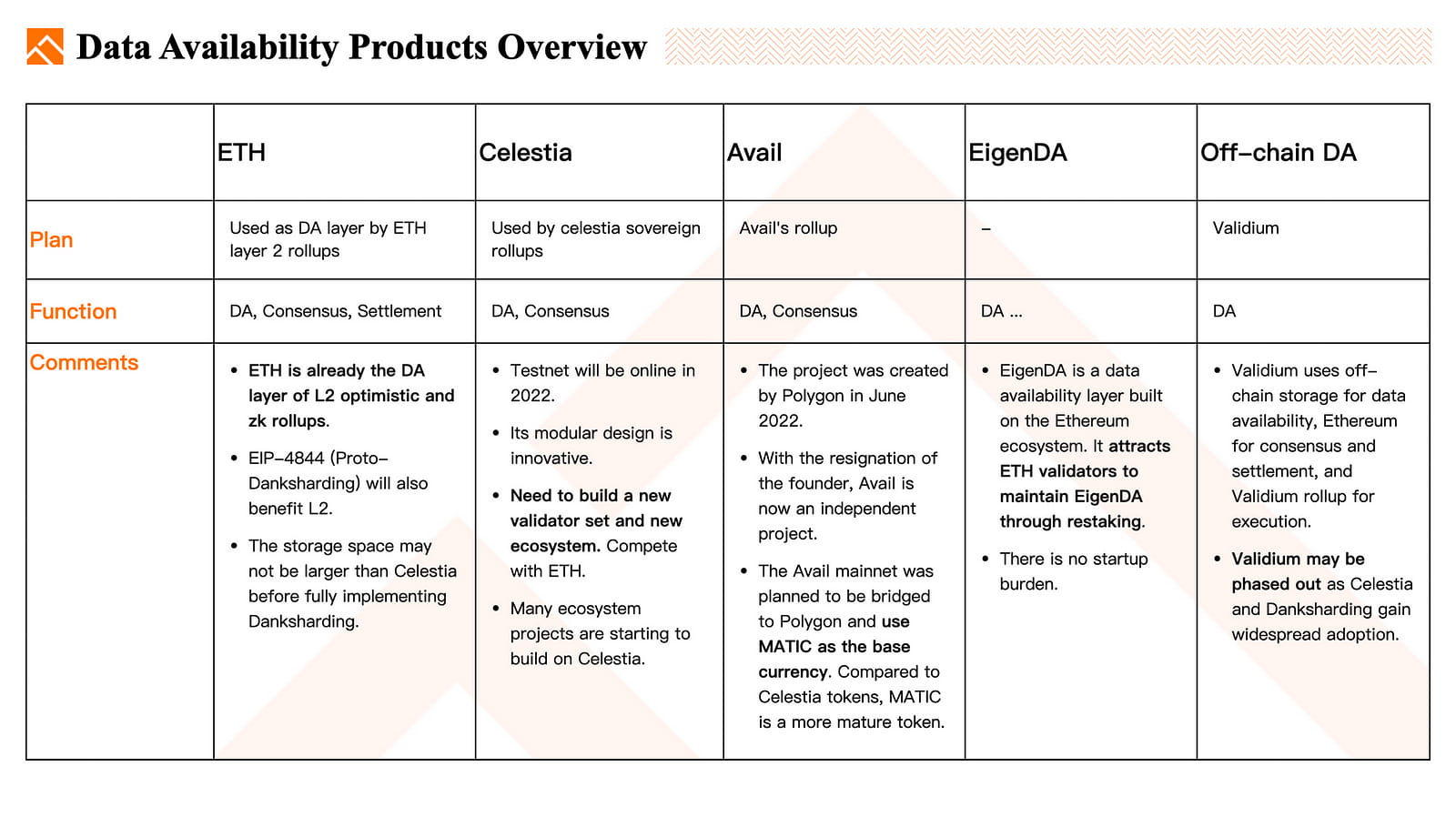
Die Übersicht der Datenverfügbarkeitsprodukte.
ETH: ETH dient derzeit als Datenverfügbarkeitsschicht für L2-Optimistic-Rollups und ZK-Rollups. Die Einführung von EIP4844 (Proto-Danksharding) wird L2 zusätzliche Vorteile bieten. Obwohl die Speicherkapazität von ETH möglicherweise nicht so groß ist wie die von Celestia, wird sie vergleichbar sein, sobald Danksharding vollständig implementiert ist.
Celestia: Celestia ist als Konsens- und Datenverfügbarkeitsschicht konzipiert. Das Celestia-Testnetz ging im Juni 2022 online und erfreut sich aufgrund seines innovativen modularen Designs seit 2022 zunehmender Beliebtheit. Celestia muss ein eigenes Ökosystem aufbauen und in einem Wettbewerbsverhältnis zu Ethereum bestehen. Viele Projekte basieren auf Celestia.
Avail: Avail wurde ursprünglich im Juni 2022 von Polygon eingeführt. Nach dem Ausscheiden seines Gründers aus Polygon wurde Avail jedoch zu einem unabhängigen modularen Blockchain-Projekt und es wurde ein Testnetz veröffentlicht. Avail ist eine eigenständige Konsens- und DA-Schicht wie Celestia. Das Avail-Mainnet sollte mit Polygon verbunden werden und MATIC als Basiswährung verwenden. Im Vergleich zu Celestia-Token ist MATIC ein ausgereifterer Token.
EigenDA: EigenDA ist eine Ethereum-basierte DA-Schicht, die Validierer dazu anregt, das Netzwerk durch ETH-Restaking aufrechtzuerhalten, wodurch ein Startaufwand wie bei Celestia entfällt.
Andere Off-Chain-DA: Validium verwendet Off-Chain-Speicher für die Datenverfügbarkeit, Ethereum für Konsens und Abwicklung und Validium-Rollup für die Ausführung. Validium wird möglicherweise auslaufen, da Celestia und Danksharding zunehmende Verbreitung finden.
Zusammenfassend denken wir,
Eine Datenverfügbarkeitsschicht ist ein vielversprechender und wichtiger Ansatz zur Skalierung von Blockchains.
Die aktuellen DA-Produkte haben ihre eigenen Vorteile und sie alle verdienen kontinuierliche Aufmerksamkeit.
Die Technologie von Celestia muss noch vom Markt bestätigt werden und es ist möglich, dass ETH und Celestia in Zukunft auch technisch zusammenwachsen.

4. Dezentrale Berechnung
Obwohl wir einige dezentrale Computerprojekte beobachtet haben, glauben wir, dass sich die Entwicklung des dezentralen Computing noch in den Kinderschuhen befindet. Eine der größten Herausforderungen in diesem Bereich ist die Überprüfung der Genauigkeit der Berechnungen.

Mehr erklären
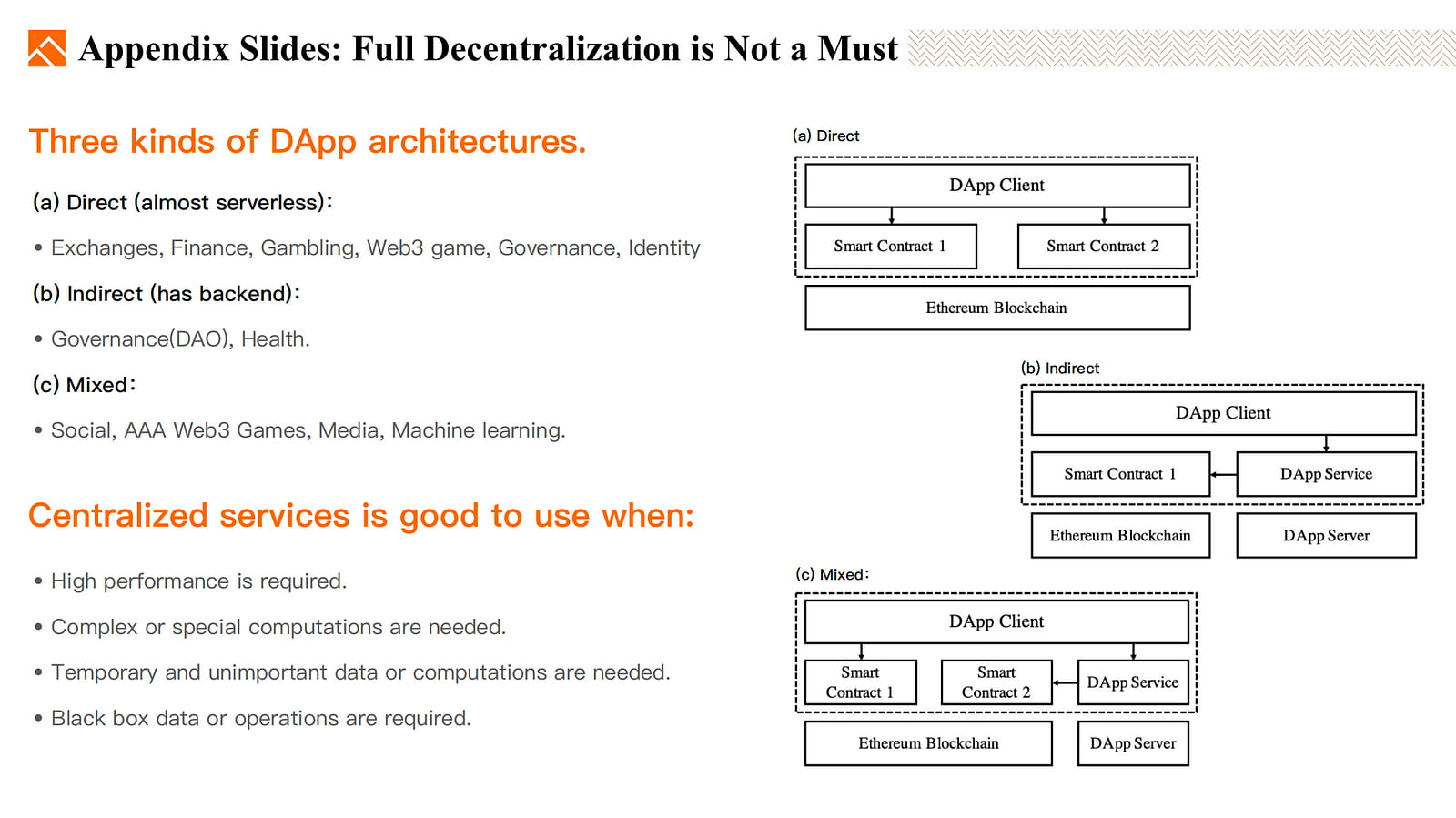
Eine vollständige Dezentralisierung ist nicht immer notwendig. Derzeit sind drei Haupttypen von DApp-Architekturen verfügbar. Zentralisierte Dienste können in Situationen von Vorteil sein, in denen hohe Leistung erforderlich ist und beliebig komplexe Berechnungen durchgeführt werden müssen.
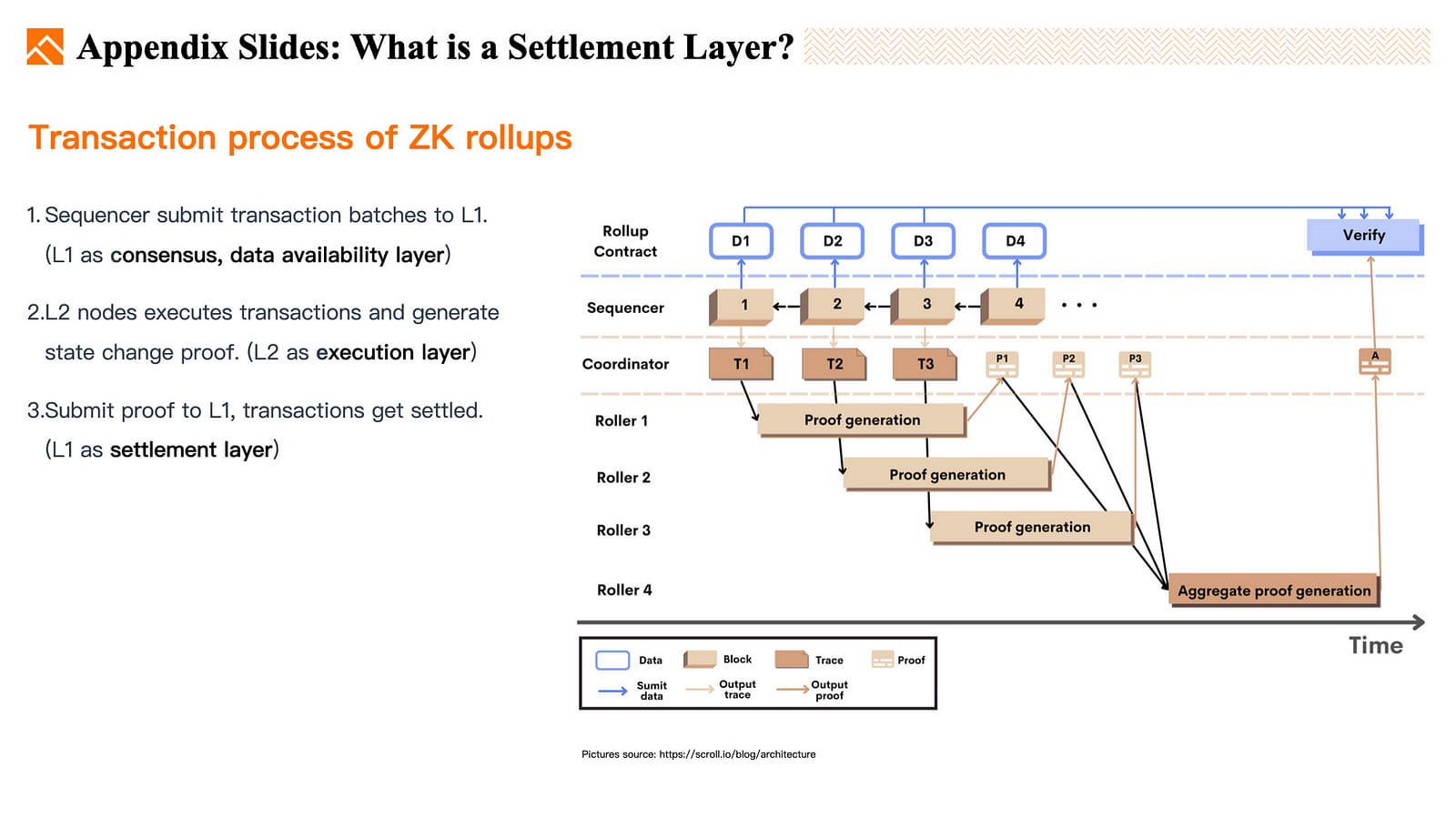
Es scheint, dass einige Personen die Unterschiede zwischen der Konsensschicht und der Abwicklungsschicht nicht vollständig verstehen. Zur Verdeutlichung werde ich die vier Funktionen in der Blockchain am Beispiel von Ethereums ZK Rollup erläutern.
Nachdem Transaktionen auf Layer 2 stattgefunden haben, werden sie an den Sequencer übermittelt, der sie bündelt und zusammenfasst, bevor er sie an den Smart Contract auf der ETH-Blockchain übermittelt. Wenn das Rollup zur ETH-Kette hinzugefügt wird, wird der Konsens über die Reihenfolge der Transaktionen bestätigt und ETH wird zur Konsensebene des Rollups. Da Layer-2-Transaktionen auf der ETH-Blockchain gespeichert werden, dient ETH auch als DA-Ebene (Data Availability) für Layer 2.
Layer-2-Knoten führen die Transaktionsausführung durch, ändern den globalen Status von Layer 2 und generieren Zero-Knowledge-Beweise. Layer 2 dient als Ausführungsebene.
Layer 2 übermittelt den ZKP an ETH, wo der ETH-Vertrag dessen Gültigkeit bestätigt. Sobald der Nachweis akzeptiert ist, wird der neue Status von Layer 2 bestätigt. ETH dient als Abwicklungsebene für das Layer 2-ZK-Rollup.
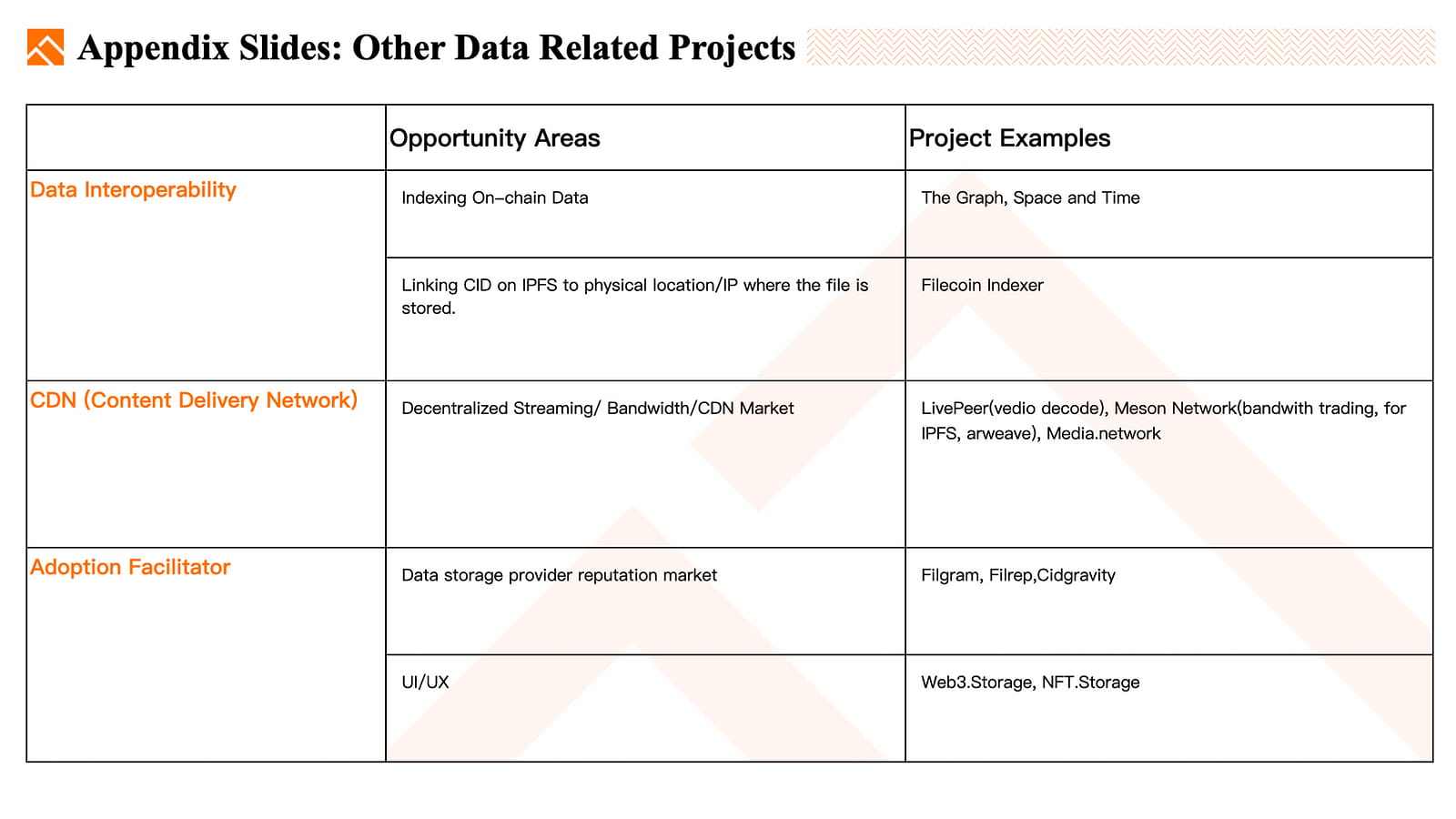
Es gibt noch weitere Arten datenbezogener Projekte, beispielsweise:
Projekte, die sich auf die Indizierung von On-Chain-Daten wie The Graph und Space and Time oder die Indizierung von IPFS-Daten wie Filecoin Indexer konzentrieren.
DNS-Netzwerke, einschließlich LivePeer, Meson Network, Media.network und andere.
Märkte zur Reputation von Speicherknoten wie Filgram, Filrep und Cidgravity, mit UI/UX-Beispielen wie Web3.storage und NFT.storage.
Über Foresight Ventures
Foresight Ventures hat sich zum Ziel gesetzt, die bahnbrechende Innovation der Blockchain in den nächsten Jahrzehnten zu unterstützen. Wir verwalten mehrere Fonds: einen VC-Fonds, einen aktiv verwalteten Sekundärfonds, einen Multi-Strategie-FOF und einen privaten Sekundärmarktfonds mit einem verwalteten Vermögen von über 400 Millionen US-Dollar. Foresight Ventures hält an der Überzeugung einer „einzigartigen, unabhängigen, aggressiven und langfristigen Denkweise“ fest und bietet umfassende Unterstützung für Portfoliounternehmen innerhalb eines wachsenden Ökosystems. Unser Team besteht aus Veteranen führender Finanz- und Technologieunternehmen wie Sequoia Capital, CICC, Google, Bitmain und vielen anderen.
Website: https://www.foresightventures.com/
Twitter: https://twitter.com/ForesightVen
Medium: https://foresightventures.medium.com
Substack: https://foresightventures.substack.com
Discord: https://discord.com/invite/maEG3hRdE3
Linktree: https://linktr.ee/foresightventures
Haftungsausschluss: Alle Artikel von Foresight Ventures stellen keine Anlageberatung dar. Einzelpersonen sollten ihre eigene Risikobereitschaft beurteilen und Anlageentscheidungen umsichtig treffen.