
@Walrus 🦭/acc Daten sicher zu halten, ist eines dieser Themen, das nur langweilig klingt, bis der Tag kommt, an dem es das nicht mehr tut. In dem Moment, in dem etwas verschwindet, sich gabelt oder leise aus dem Gleichgewicht gerät, wird einem klar, wie sehr das moderne Leben davon abhängt, dass Speicher wie ein Versprechen funktioniert. Deshalb erhält die dezentrale Speicherung gerade jetzt erneute Aufmerksamkeit. Anwendungen wollen die Prüfbarkeit und die gemeinsame Kontrolle von Blockchains, aber sie müssen auch große Dateien – Medien, Datensätze und Modellartefakte – verarbeiten, ohne die Kosten für die Replikation alles überall zu zahlen oder rohe Bytes direkt auf der Kette zu speichern.
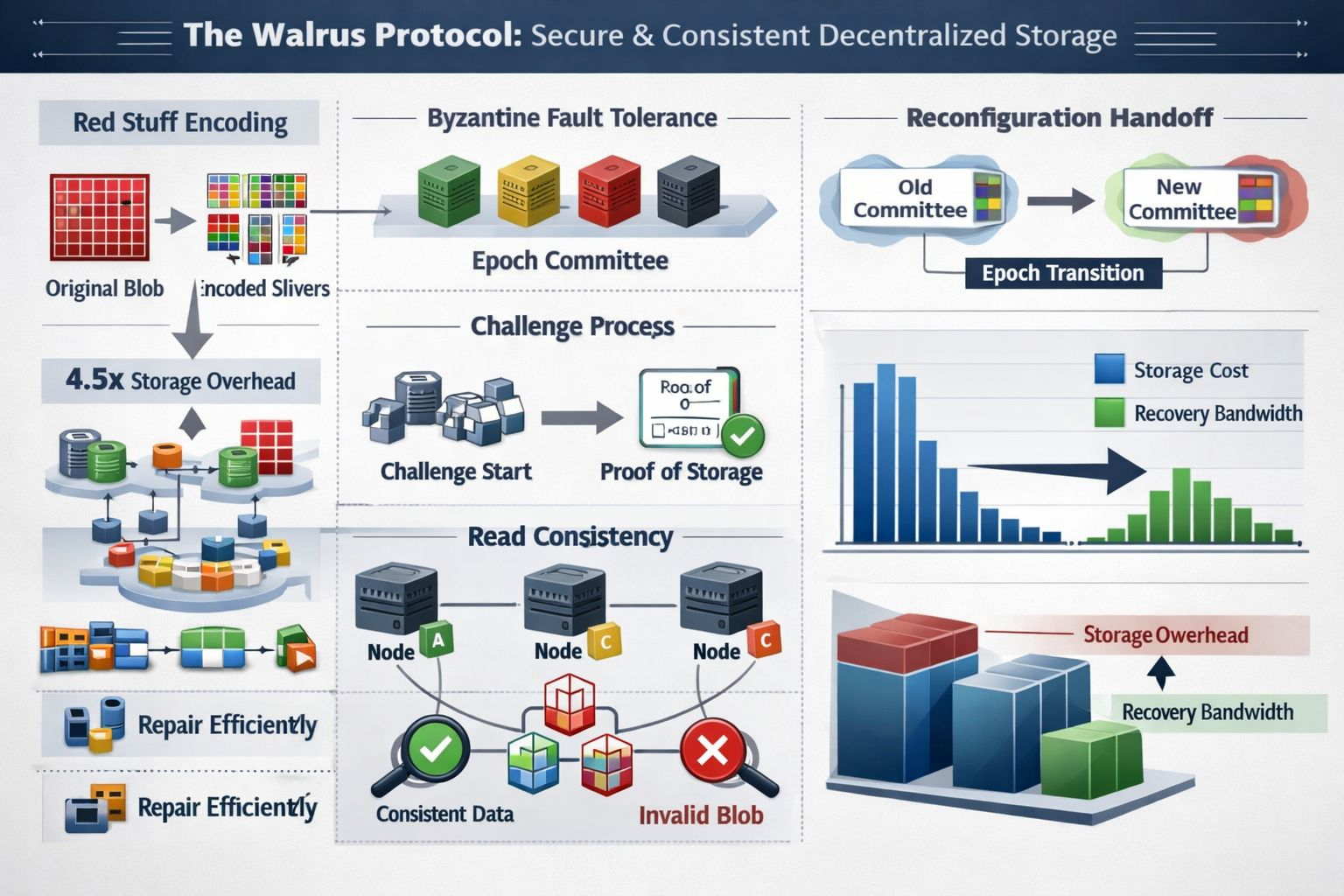
Walrus ist ein Versuch, dieses Versprechen konkreter zu machen mit einem Protokoll, das von wenig schmeichelhaften Annahmen ausgeht. Es wird angenommen, dass einige Speicher-Knoten fehlerhaft oder böswillig sind, und es wird angenommen, dass das Netzwerk asynchron sein kann: Nachrichten können verzögert oder neu angeordnet werden. Das Design ist in Epochen organisiert, in denen ein fester Ausschuss von Speicherknoten für eine bestimmte Zeit verantwortlich ist, Daten unter einem byzantinischen Fehlermodell zu speichern. Diese Wahl ist wichtig, weil sie das System zwingt zu definieren, was „sicher“ bedeutet, selbst wenn Teile des Netzwerks nicht kooperativ sind.
Im Mittelpunkt steht eine Kodierungsmethode namens Red Stuff, die als zweidimensionales Löschkodierungsschema beschrieben wird. Anstelle einer vollständigen Replikation wird ein Blob in kodierte „Fragmente“ umgewandelt, die über Knoten verteilt sind, und ein Leser rekonstruiert den ursprünglichen Blob aus genügend Fragmenten. Das Walrus-Papier berichtet von hoher Sicherheit mit einem Speicherüberhang von etwa 4,5× und unterstützt die Wiederherstellung, bei der die Bandbreite, die verwendet wird, um fehlende Teile zu reparieren, proportional zu dem ist, was tatsächlich verloren ging, nicht zur Größe des gesamten Blobs. Das ist die Art von Detail, die akademisch klingt, bis man den Wechsel sieht – Knoten verlassen, Knoten fallen aus – und erkennt, wie schnell „billiger Speicher“ zu „teurem Reparaturverkehr“ in vielen echten Systemen wird.
Aber Konsistenz ist mehr als „können wir die Bytes wiederherstellen“. Walrus betrachtet die Lese-Konsistenz als ein erstklassiges Ziel: Selbst wenn ein Schreiber böswillig ist, sollten korrekte Leser keine unterschiedlichen Daten rekonstruieren, je nachdem, mit welchen Knoten sie in Kontakt kommen. Das Papier bindet dies an Verpflichtungen und authentifizierte Strukturen, sodass das, was Sie abrufen, gegen das geprüft werden kann, was zum Schreibzeitpunkt verpflichtet wurde. Es beschreibt auch, wie Knoten inkonsistente Kodierungen durch einen böswilligen Client erkennen und überprüfbare Beweise produzieren können, sodass das Netzwerk auf „dieses Blob ist ungültig“ konvergieren kann, anstatt stillschweigend unterschiedliche Versionen bereitzustellen. Ich neige dazu, Designs mehr zu vertrauen, wenn sie diese unangenehme Wahrheit eingestehen: Manchmal ist der Feind kein Knoten, der lügt, sondern ein Schreiber, der versucht zu verwirren.
Der Beweis ist der Punkt, an dem dezentrale Systeme oft unangenehm werden, denn Anreize allein verhindern nicht, dass ein Knoten vorgibt, was nicht der Fall ist. Walrus verwendet Speicherherausforderungen und versucht, dies zu tun, ohne anzunehmen, dass das Netzwerk schön synchronisiert ist. Im asynchronen Herausforderungsfluss des Papiers löst ein On-Chain-„Herausforderungsstart“-Ereignis Bestätigungen aus, ein Zufallszahlensaat hilft dabei, auszuwählen, welche Blobs herausgefordert werden, und herausgeforderte Knoten müssen die richtigen Fragmente produzieren und Unterschriften sammeln, um ein On-Chain-Zertifikat für den Speicher zu erstellen. Der Punkt ist einfach: Hoffe nicht nur, dass Knoten die Daten gespeichert haben – zwinge sie, es unter Bedingungen zu demonstrieren, in denen Timing-Tricks weniger nützlich sind.
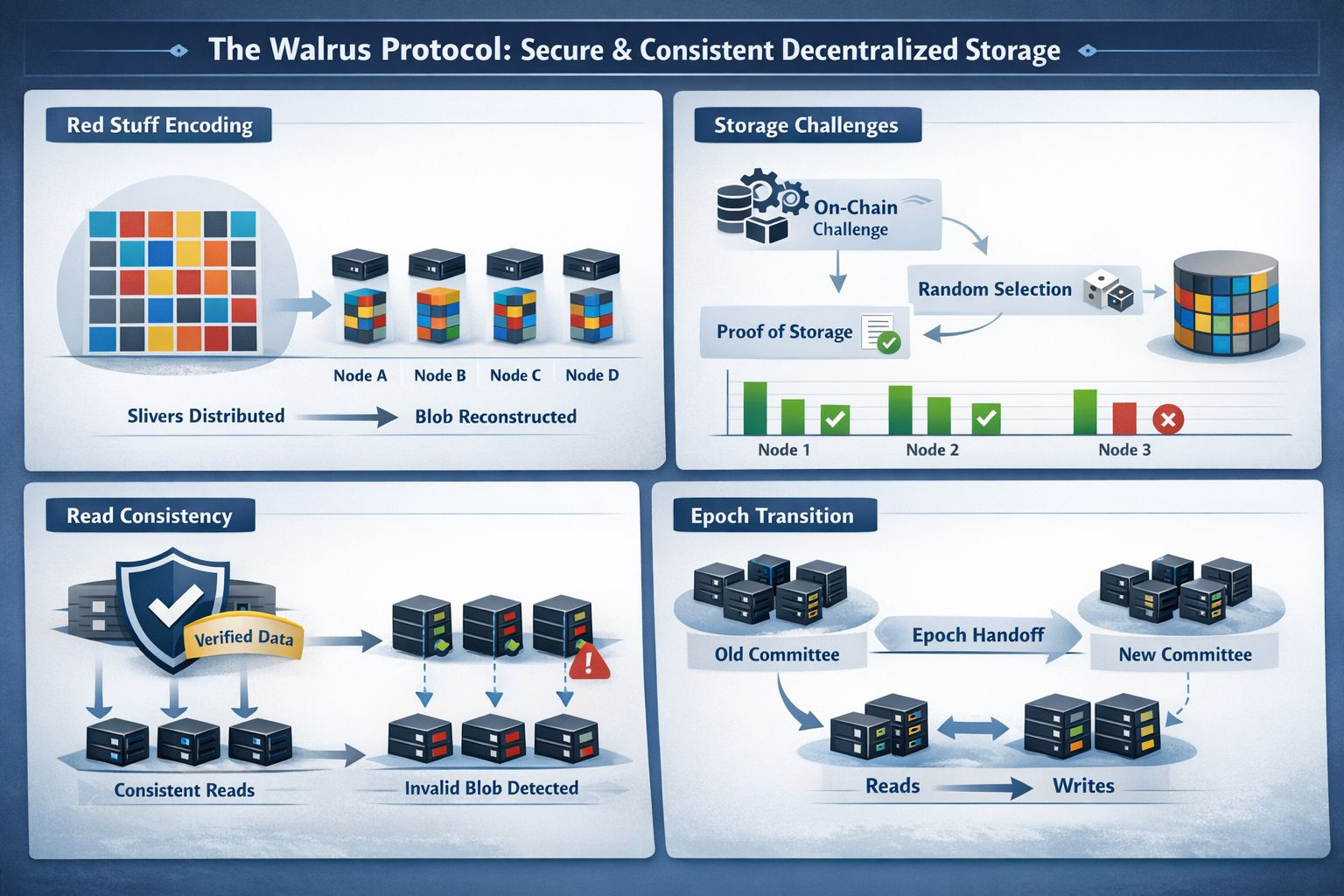
Der weniger glamouröse, aber wesentliche Teil ist, was passiert, wenn Ausschüsse wechseln. Walrus-Rekonfiguration versucht, Ausfallzeiten zu vermeiden, indem Verantwortlichkeiten während des Übergangs aufgeteilt werden: Wenn die Rekonfiguration beginnt, gehen Schreibvorgänge an den nächsten Ausschuss, während Lesevorgänge beim alten bleiben, und Blob-Metadaten geben die Epoche an, in der sie erstmals geschrieben wurden, damit die Clients während der Überlappung wissen, wo sie suchen sollen. Diese Art von ingenieurtechnischem Kompromiss ist leicht zu übersehen, aber Übergänge sind der Punkt, an dem Systeme ihre wahre Konsistenzgeschichte offenbaren.
Es ist auch kein Zufall, dass Walrus jetzt besprochen wird. Walrus startete das Mainnet Ende März 2025 und zog mit einer großen Finanzierungsrunde, die von Medien wie CoinDesk und Fortune behandelt wurde, Aufmerksamkeit auf sich. Noch wichtiger ist, dass das Timing mit der breiteren Nachfrage übereinstimmt: datenintensive Apps wollen programmierbare Regeln für Off-Chain-Bytes, und Walrus geht darauf ein, indem es gespeicherte Blobs so darstellt, dass Apps sie über Smart Contracts verwalten können, während die umfangreichen Daten Off-Chain bleiben. Der Trend ist nicht einfach „mehr Daten“. Es geht um mehr Verantwortlichkeit für Daten – wer besitzt sie, wie lange leben sie, wie werden sie verifiziert – ohne in einen einzigen vertrauenswürdigen Speicheranbieter zurückzufallen.
Nichts davon bedeutet, dass das Risiko verschwunden ist. Jedes Design, das Kryptografie, Anreize und Live-Rekonfiguration mischt, hat scharfe Kanten, und der echte Test ist, wie es sich unter Stress verhält: ungleiche Anreize, hässliche Netzwerkpartitionen oder Arbeitslasten, die nicht mit dem glücklichen Pfad übereinstimmen. Trotzdem schätze ich den Walrus-Instinkt, „Daten sicher zu halten“ in überprüfbare Schritte zu zerlegen – codieren, verpflichten, Verfügbarkeit zertifizieren, herausfordern, wiederherstellen – denn Sicherheit hört auf, ein Gefühl zu sein, und wird zu etwas, das Sie tatsächlich überprüfen können.