
@Walrus 🦭/acc Keeping data safe is one of those topics that only sounds dull until the day it isn’t. The moment something disappears, forks, or quietly drifts out of sync, you realize how much modern life depends on storage behaving like a promise. That’s why decentralized storage is getting renewed attention right now. Applications want the auditability and shared control of blockchains, but they also need to handle large files—media, datasets, and model artifacts—without paying the cost of replicating everything everywhere or stuffing raw bytes directly on chain.
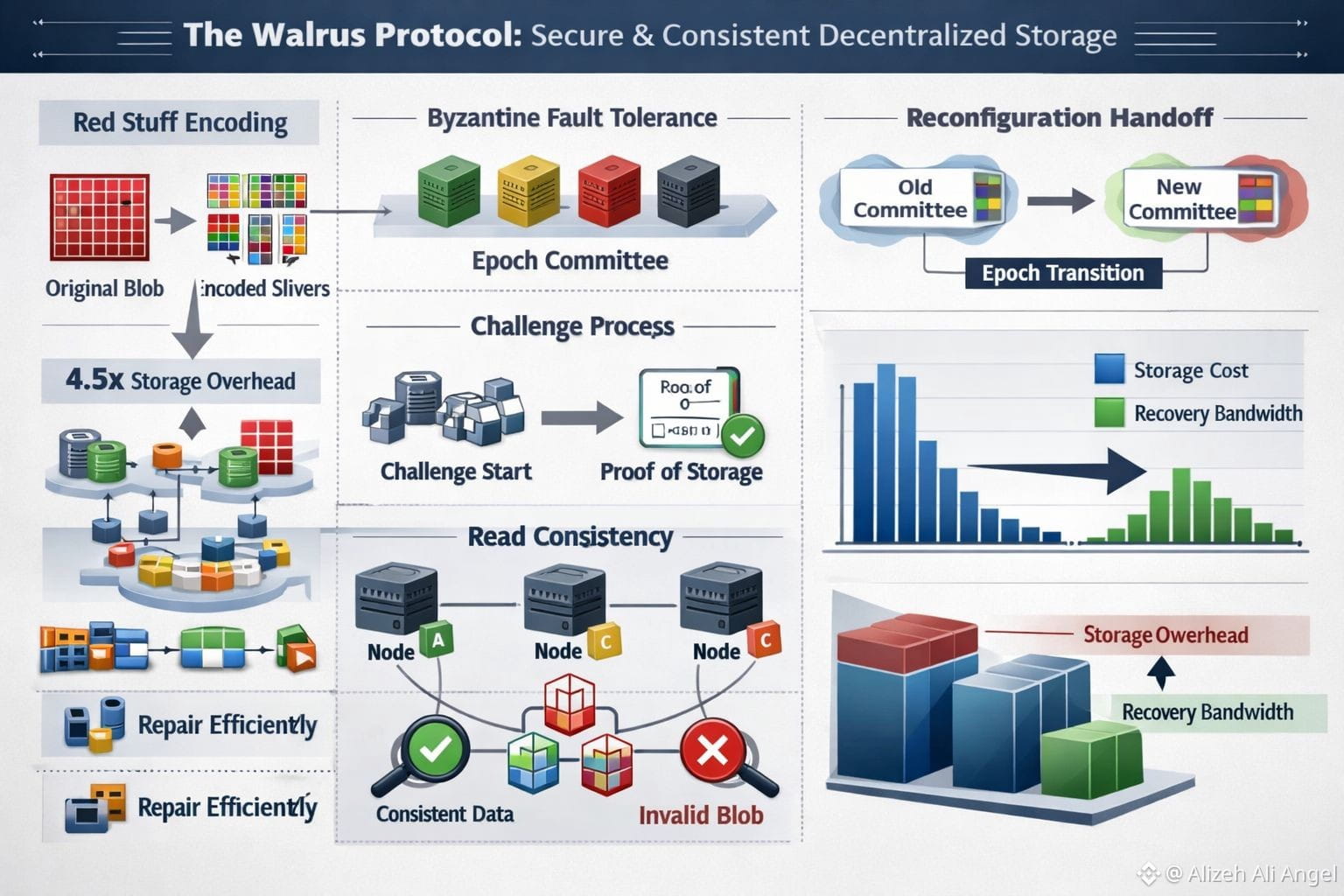
Walrus is one attempt to make that promise more concrete with a protocol that starts from unflattering assumptions. It assumes some storage nodes will be faulty or malicious, and it assumes the network can be asynchronous: messages may be delayed or reordered. The design is organized into epochs, where a fixed committee of storage nodes is responsible for storing data for a period of time under a Byzantine fault model. That choice matters because it forces the system to define what “safe” means even when parts of the network are uncooperative.
At the center is an encoding method called Red Stuff, described as a two-dimensional erasure coding scheme. Instead of full replication, a blob is transformed into encoded “slivers” spread across nodes, and a reader reconstructs the original blob from enough slivers. The Walrus paper reports high security with roughly a 4.5× storage overhead and supports recovery where the bandwidth used to repair missing pieces is proportional to what was actually lost, not the size of the entire blob. That’s the kind of detail that sounds academic until you picture churn—nodes leaving, nodes failing—and realize how quickly “cheap storage” becomes “expensive repair traffic” in many real systems.
But consistency is more than “can we rebuild the bytes.” Walrus treats read consistency as a first-class goal: even if a writer is malicious, correct readers shouldn’t reconstruct different data depending on which nodes they happen to contact. The paper ties this to commitments and authenticated structures so that what you retrieve can be checked against what was committed at write time. It also describes how nodes can detect inconsistent encoding by a malicious client and produce verifiable evidence, so the network can converge on “this blob is invalid” instead of silently serving different versions. I tend to trust designs more when they admit this uncomfortable truth: sometimes the enemy isn’t a node that lies, it’s a writer that tries to confuse.
Proof is where decentralized systems often get uncomfortable, because incentives alone don’t stop a node from pretending. Walrus uses storage challenges and tries to do it without assuming the network is nicely synchronous. In the paper’s asynchronous challenge flow, an on-chain “challenge start” event triggers acknowledgments, a randomness seed helps select which blobs get challenged, and challenged nodes must produce the correct slivers and collect signatures to form an on-chain certificate of storage. The point is simple: don’t just hope nodes stored the data—force them to demonstrate it under conditions where timing tricks are less useful.
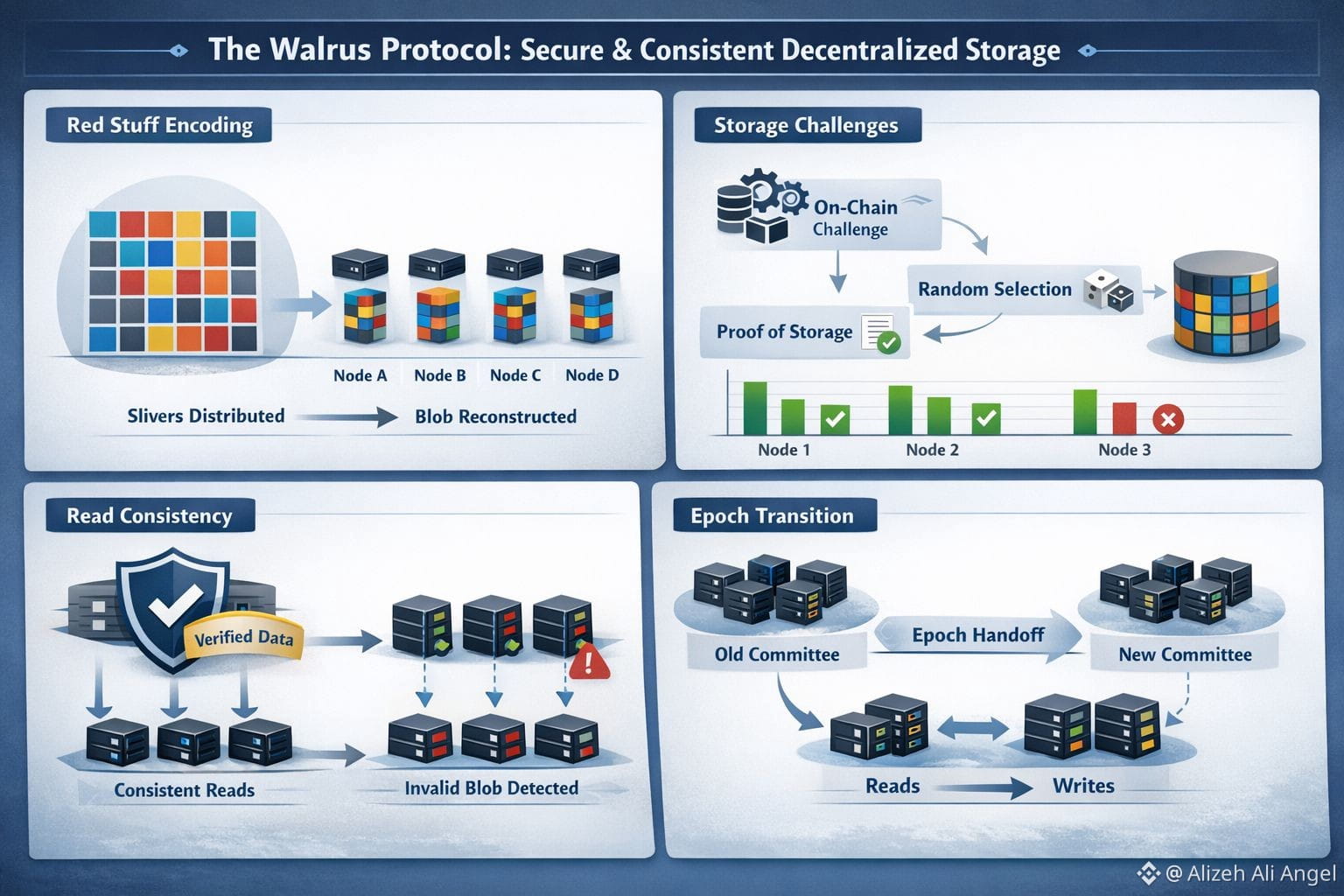
The less glamorous but essential piece is what happens when committees change. Walrus reconfiguration tries to avoid downtime by splitting responsibilities during handover: as reconfiguration begins, writes go to the next committee while reads remain on the old one, and blob metadata indicates the epoch it was first written so clients know where to look during the overlap. That kind of engineering compromise is easy to overlook, but transitions are where systems reveal their true consistency story.
It’s also not an accident that Walrus is being talked about now. Walrus launched mainnet in late March 2025 and drew attention with a large fundraising round covered by outlets like CoinDesk and Fortune. More importantly, the timing matches broader demand: data-heavy apps want programmable rules around off-chain bytes, and Walrus leans into that by representing stored blobs in a way that apps can manage via smart contracts while keeping the bulk data off-chain. The trend isn’t just “more data.” It’s more accountability for data—who owns it, how long it lives, how it’s verified—without collapsing back into a single trusted storage provider.
None of this means the risk is gone. Any design that mixes cryptography, incentives, and live reconfiguration has sharp edges, and the real test is how it behaves under stress: uneven incentives, ugly network partitions, or workloads that don’t match the happy path. Still, I appreciate the Walrus instinct to break “keeping data safe” into verifiable steps—encode, commit, certify availability, challenge, recover—because safety stops being a vibe and starts being something you can actually check.