

Walrus does not get tested when everything is cold and polite.
@Walrus 🦭/acc gets tested when one blob turns into a hard requirement.
The moment an object flips from "nice to have" to 'if this doesn't load, we are eating it publicly", the word stored stops helping. You can say it is on the network as many times as you want. What your team gets back is tail latency in Grafana and "still spinning" in support. Tail latency doesn't care that the blob is technically safe.
It doesn't care at all though.
I've seen this scene play out with different stacks. The tell is always the same... the first report isn't "data loss". This is "it’s slow for some people" thung.. Then "it’s slow again". Then the support channel fills with screenshots of spinners, because users don't file tickets with root causes. They file tickets with feelings.
A reveal image. A patch. A dataset link that suddenly becomes the input for a pile of jobs. The blob didn't change. The access pattern did change somehow. Everyone hits it at once, then hits it again because it felt uncertain... and that second wave is the part teams forget to price in. Retries aren't neutral. They're demand multipliers.
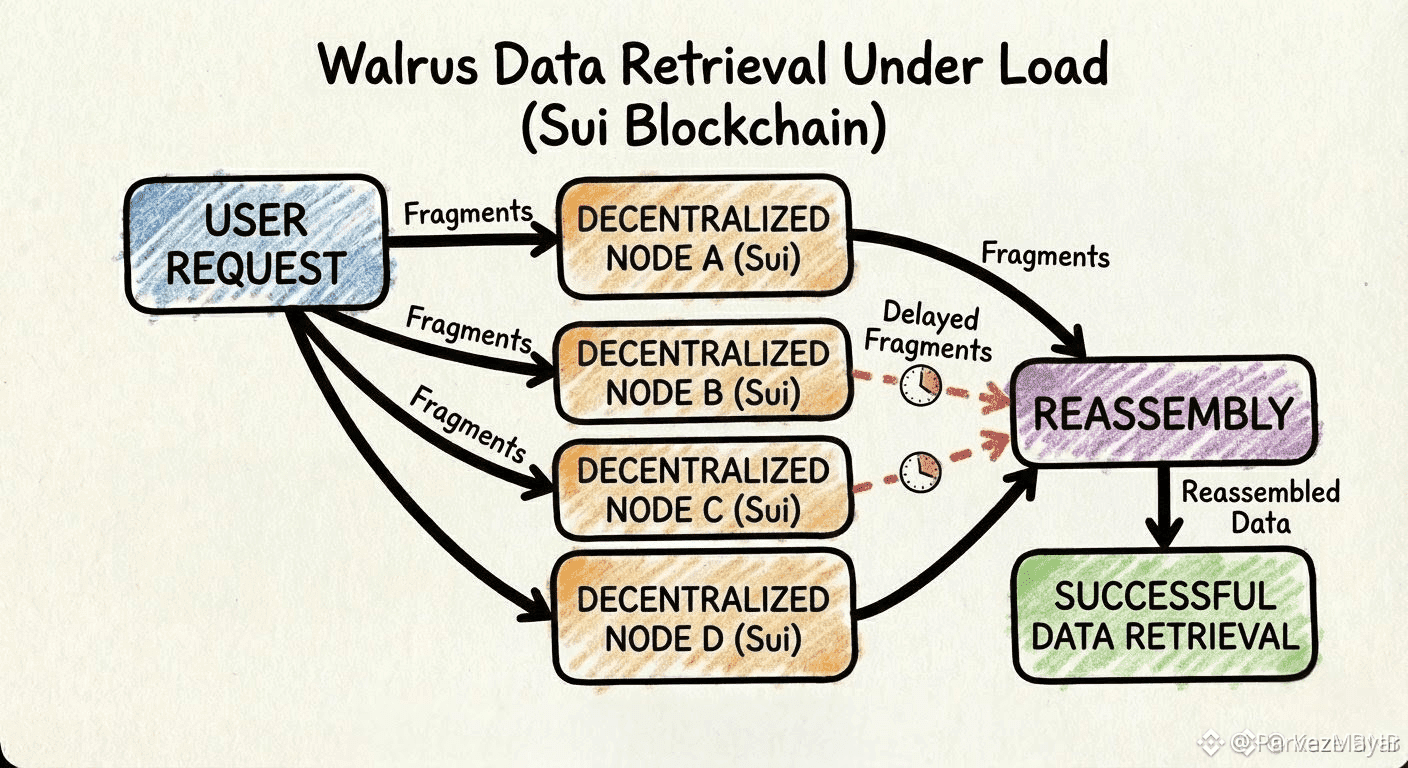
On Walrus, burst looks like a reassembly problem, not a cute “'high QPS" chart. Big blobs arrive as pieces that have to be fetched and stitched back together, and the slowest stripe is the one that sets the user experience. You can have enough pieces in aggregate and still miss the moment because the last few are stuck behind the same congested routes, or the same handful of operators that everyone is leaning on at once.
Sometimes it's not even a timeout. It is worse than that timeout. Everything returns… just late enough that your frontend's "fallback" kicks in and you have doubled the load for free.
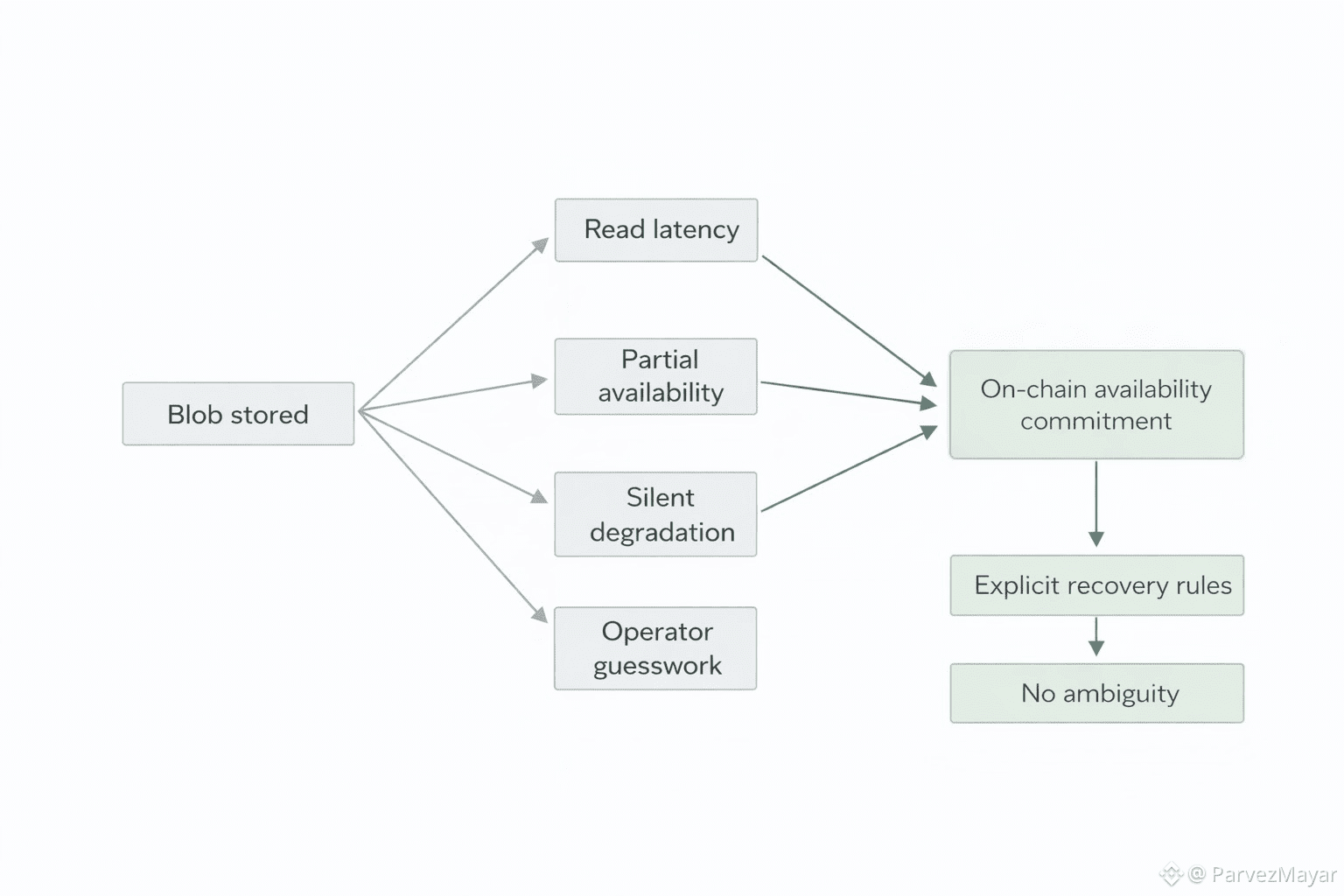
You'll still be able to say, with a straight face, that the blob is reconstructible. That it exists. That the system is doing what it promised. Meanwhile the user-facing truth is uglier... the fast path turns inconsistent and your product starts paying for tail risk.
Teams try to rationalize it at first. You hear the coping lines... it's only peak. It is only some regions. "it's fine, it eventually loads. Eventually is not a user experience. Eventually is a bug report with better branding.
Every team knows that, they just don't admit... But not with Walrus protocol.
And Walrus isn't operating in a vacuum when this happens. The network is not waiting politely for your launch. Pieces drift. Redundancy gets restored. Repairs keep running while life keeps moving. Then your blob goes hot and reads collide with repair traffic.. and both start queueing behind the same operator bandwidth and scheduling limits. The symptom is boring and familiar: queue depth rises, p95 looks "manageable", and p99 turns into a support problem.
The builder reaction here is honest and quiet. Nobody writes a manifesto about it. They change defaults.
They start treating retrieval as its own primitive, even if the diagram still shows one box. They get picky about what's allowed on the critical path. They warm caches before launches. They pre-stage what matters. They restructure flows so the moment that must feel instant does nott depend on a fetch that might wander into the slow lane under burst.
Honestly this is not ideology. it is self-defense.
After one bad window, the "temporary' rules stay. The cache stays. The mirror stays. And 'stored' stops meaning safe to depend on when it counts. It just means "it exists somewhere... and you'd better plan for the day it comes back late."


